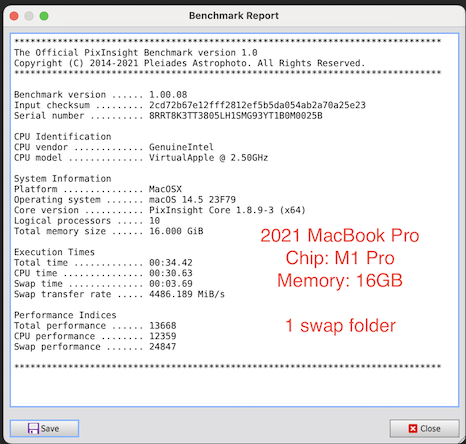
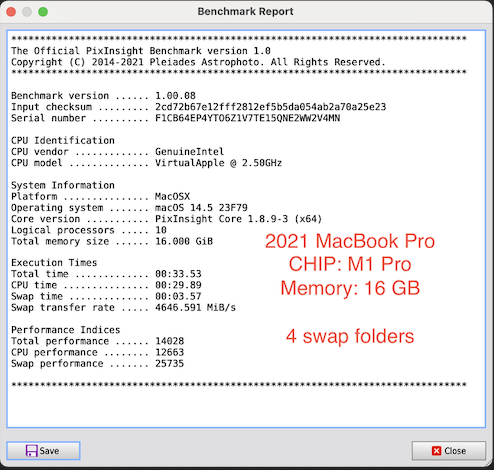
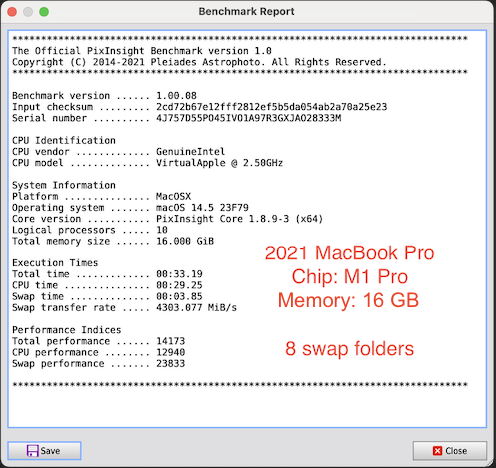
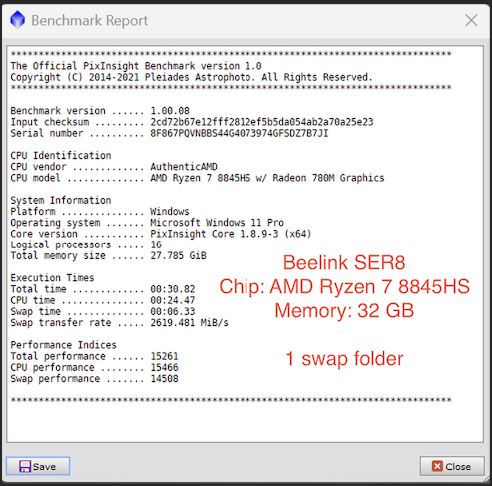
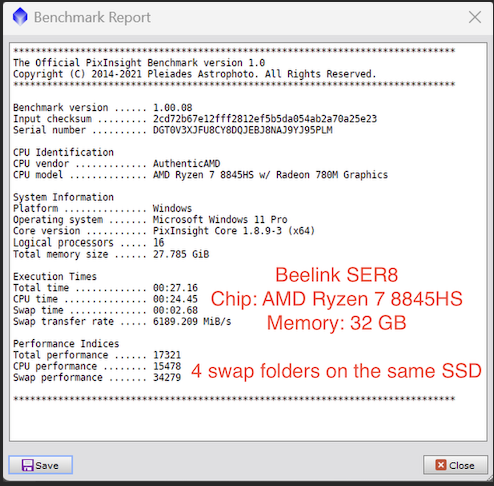
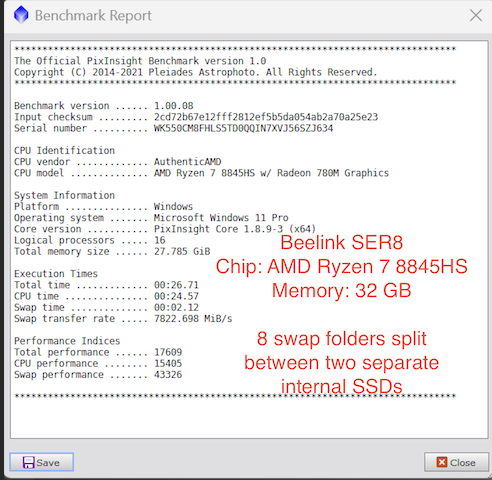
AstroShed:
If it is against any rules or people are really not happy then I will gladly take it down.
Also I am not posting to farm views, I am posting as I thought it was maybe good information and possibly helpful….but like I say I am happy to remove if people are really not happy….👍🏻 Dude, you keep right on posting your videos here. I found your video very useful. I already knew from my lessons with Ron Brecher, the Astrodoc (<--shameless, deliberate plug for my friend and mentor to help him make money while actually helping others), about setting up multiple references to the swap folder. But what did NOT occur to me until watching your video was spreading the references across multiple SSDs. And your video didn't cost me a cent. I have four SSDs on my system, but the C: and D: drives are much faster than E: and F:. I first tried four references to each drive. That actually resulted in a 60% slowdown. But then I remembered that C: and D: are NVMe and the others are not. When I changed it to 8 references to C: and 8 to D:, that resulted in a speed increase of the advertised 30% over what I had with 16 references to D: only. So thank you so much for that! And just FYI, there is a person on this thread, who shall go nameless, who has appointed himself Astrobin Police. This isn't the first thread where he's weighed in inappropriately with his negative energy. Pay zero attention to him. He has nothing of value to offer. And he doesn't speak for anyone but himself. You, however, are doing the Lord's work here. Keep it up!
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Joseph Biscoe IV:
Dark Matters Astrophotography:
Is posting videos to farm views really an appropriate use of Astrobin forums?
Just curious, but how would you have done it?
it seems like you’re making a ridiculous assumption to claim that @AstroShed is trying to “farm views”. Should we infer that it would be better to download the transcript from the video and post it as a pdf?
Anyway, thanks for the info @AstroShed i had originally thought that it needed different folders on different drives. Loading in the same drive multiple times on two of my loaded drives brought me down to 2.50” of swap speed. Very nice! Thanks… yes many people did not realise that it actually makes more of a difference when the same folder is added multiple times to a drive, and this is also recommended by the PI team in the pop up box that comes up on that page in PI glad you found it useful 👍🏻
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Timothy Martin:
AstroShed:
If it is against any rules or people are really not happy then I will gladly take it down.
Also I am not posting to farm views, I am posting as I thought it was maybe good information and possibly helpful….but like I say I am happy to remove if people are really not happy….👍🏻
Dude, you keep right on posting your videos here. I found your video very useful. I already knew from my lessons with Ron Brecher, the Astrodoc (<--shameless, deliberate plug for my friend and mentor to help him make money while actually helping others), about setting up multiple references to the swap folder. But what did NOT occur to me until watching your video was spreading the references across multiple SSDs. And your video didn't cost me a cent.
I have four SSDs on my system, but the C: and D: drives are much faster than E: and F:. I first tried four references to each drive. That actually resulted in a 60% slowdown. But then I remembered that C: and D: are NVMe and the others are not. When I changed it to 8 references to C: and 8 to D:, that resulted in a speed increase of the advertised 30% over what I had with 16 references to D: only. So thank you so much for that!
And just FYI, there is a person on this thread, who shall go nameless, who has appointed himself Astrobin Police. This isn't the first thread where he's weighed in inappropriately with his negative energy. Pay zero attention to him. He has nothing of value to offer. And he doesn't speak for anyone but himself. You, however, are doing the Lord's work here. Keep it up! Thank you very much for that, much appreciated…👍🏻 Also I am glad you found it useful and got a really good result…I actually need to change my own set up since making the video, and seeing the results posted here, as I have just one NVME and 2 sata hard drives, which I think, using the sata drives is actually slowing mine down, compared to some of the results shown here, maybe I should just use the NVME and add all 12 swap folders on that….🤔
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Here is my score, Lenovo Legion 5 laptop. 8 swap on two disks. With the original swap file I had a score of 24000ish. https://pixinsight.com/benchmark/benchmark-report.php?sn=8TPXP6ET94P503DPIMK7VTRR5L40D5BYCPU IdentificationCPU vendorGenuineIntelCPU model13th Gen Intel(R) Core(TM) i7-13650HXSystem InformationPlatformWindowsOperating systemMicrosoft Windows 11 HomeCore versionPixInsight Core 1.8.9-3 (x64)Logical processors20Total memory size63.715 GiBExecution TimesTotal time17.88 sCPU time14.91 sSwap time2.95 sSwap transfer rate5620.140 MiB/sPerformance Indexes - Total performance26312
- CPU performance25384
- Swap performance31127
- Additional InformationSwap disks1 TB Samsung 980 ProMotherboard Machine descriptionLenovo 5 laptop 16IRX9CommentsStandard Lenovo 5 with Intel i7-13650HX and 64GB ram.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Joseph Biscoe IV:
John Hayes:
Interesting. I tried this on my MacBook Pro M2 with a 2TB SSD and it made essentially zero difference.
It would be nice if, when reporting results, participants would provide information about their hardware.
John
you can extrapolate that information by the OS and chipset. Or were you talking about something more specific? Sorry , I wasn't very specific was I? I had in mind the computer model and how many disks (and what type) were being used. Regardless, it looks like most folks who are reporting improvements are running Windows machines. Have you tried this on any Macs? I sure didn't see any improvement on my MacBook Pro M2 but maybe I did something wrong. John
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
John Hayes:
Joseph Biscoe IV:
John Hayes:
Interesting. I tried this on my MacBook Pro M2 with a 2TB SSD and it made essentially zero difference.
It would be nice if, when reporting results, participants would provide information about their hardware.
John
you can extrapolate that information by the OS and chipset. Or were you talking about something more specific?
Sorry , I wasn't very specific was I? I had in mind the computer model and how many disks (and what type) were being used. Regardless, it looks like most folks where are reporting improvements are running Windows machines. Have you tried this on any Macs? I sure didn't see any improvement on my MacBook Pro M2 but maybe I did something wrong.
John Did you make sure you “applied global” after setting the swap folders…?
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
AstroShed:
Did you make sure you “applied global” after setting the swap folders…? Yes. Just to be sure, I did it again. Here's the first benchmark:*******************************************************************************The Official PixInsight Benchmark version 1.0Copyright (C) 2014-2021 Pleiades Astrophoto. All Rights Reserved.******************************************************************************* Benchmark version ...... 1.00.08Input checksum ......... 2cd72b67e12fff2812ef5b5da054ab2a70a25e23Serial number .......... RS6WV4O3D88L34L98XW566HC24UE2CPM CPU IdentificationCPU vendor ............. GenuineIntelCPU model .............. VirtualApple @ 2.50GHz System InformationPlatform ............... MacOSXOperating system ....... macOS 12.4 21F79Core version ........... PixInsight Core 1.8.9-3 (x64)Logical processors ..... 10Total memory size ...... 64.000 GiB Execution TimesTotal time ............. 00:44.96CPU time ............... 00:29.11Swap time .............. 00:15.79Swap transfer rate ..... 1049.998 MiB/s Performance IndicesTotal performance ...... 10463CPU performance ........ 13003Swap performance ....... 5815******************************************************************************* Here's the second Benchmark. I added the 4 directories as instructed. Shut down and restarted and checked to make sure that the directories were still included and ran this benchmark.*******************************************************************************The Official PixInsight Benchmark version 1.0Copyright (C) 2014-2021 Pleiades Astrophoto. All Rights Reserved.******************************************************************************* Benchmark version ...... 1.00.08Input checksum ......... 2cd72b67e12fff2812ef5b5da054ab2a70a25e23Serial number .......... 8828E6HB0AB27TNQWWE1F6SGLL5XBWHE CPU IdentificationCPU vendor ............. GenuineIntelCPU model .............. VirtualApple @ 2.50GHz System InformationPlatform ............... MacOSXOperating system ....... macOS 12.4 21F79Core version ........... PixInsight Core 1.8.9-3 (x64)Logical processors ..... 10Total memory size ...... 64.000 GiB Execution TimesTotal time ............. 00:44.92CPU time ............... 00:28.70Swap time .............. 00:16.13Swap transfer rate ..... 1027.323 MiB/s Performance IndicesTotal performance ...... 10472CPU performance ........ 13187Swap performance ....... 5690******************************************************************************* As you can see, there is no meaningful difference. Also note that PI is identifying the M2 ARM chip as "GenuineIntell", which is not right...it's an Apple chip. My machine has a 2TB drive with 64GB of ram (as correctly ID'd by PI). My conclusion is that this trick does not work on the ARM equipped Apple machines. John PS AB made a complete mess of my copy/past Job here. It's too much trouble to clean it up so hopefully you can find the numbers you need. I've run into this problem before and I wish that Sal would make the effort to clean this up so that we can paste text into posts without it eliminating all of the carriage returns!
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Using my 2.5" SATA SSD (default PI installation)
*******************************************************************************
The Official PixInsight Benchmark version 1.0
Copyright (C) 2014-2021 Pleiades Astrophoto. All Rights Reserved.
*******************************************************************************
Benchmark version …… 1.00.08
Input checksum ……… 2cd72b67e12fff2812ef5b5da054ab2a70a25e23
Serial number ………. 097I86VSV36T069249CX8C9T2D3CFG00
CPU Identification
CPU vendor …………. GenuineIntel
CPU model ………….. Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz (x2)
System Information
Platform …………… Windows
Operating system ……. Microsoft Windows 10 Pro
Core version ……….. PixInsight Core 1.8.9-2 (x64)
Logical processors ….. 28
Total memory size …… 63.918 GiB
Execution Times
Total time …………. 00:52.65
CPU time …………… 00:36.42
Swap time ………….. 00:16.17
Swap transfer rate ….. 271.894 MiB/s
Performance Indices
Total performance …… 7051
CPU performance …….. 10391
Swap performance ……. 1082
*******************************************************************************
Using 1 folder on my NVME SSD
*******************************************************************************
The Official PixInsight Benchmark version 1.0
Copyright (C) 2014-2021 Pleiades Astrophoto. All Rights Reserved.
*******************************************************************************
Benchmark version …… 1.00.08
Input checksum ……… 2cd72b67e12fff2812ef5b5da054ab2a70a25e23
Serial number ………. 097I86VSV36T069249CX8C9T2D3CFG00
CPU Identification
CPU vendor …………. GenuineIntel
CPU model ………….. Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz (x2)
System Information
Platform …………… Windows
Operating system ……. Microsoft Windows 10 Pro
Core version ……….. PixInsight Core 1.8.9-2 (x64)
Logical processors ….. 28
Total memory size …… 63.918 GiB
Execution Times
Total time …………. 00:52.65
CPU time …………… 00:36.42
Swap time ………….. 00:16.17
Swap transfer rate ….. 1024.879 MiB/s
Performance Indices
Total performance …… 8935
CPU performance …….. 10391
Swap performance ……. 5676
*******************************************************************************
using 8x the same folder on my NVME SSD
*******************************************************************************
The Official PixInsight Benchmark version 1.0
Copyright (C) 2014-2021 Pleiades Astrophoto. All Rights Reserved.
*******************************************************************************
Benchmark version …… 1.00.08
Input checksum ……… 2cd72b67e12fff2812ef5b5da054ab2a70a25e23
Serial number ………. D19WKY57P647FBZH20X85368FVP70TK9
CPU Identification
CPU vendor …………. GenuineIntel
CPU model ………….. Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz
System Information
Platform …………… Windows
Operating system ……. Microsoft Windows 10 Pro
Core version ……….. PixInsight Core 1.8.9-2 (x64)
Logical processors ….. 28
Total memory size …… 63.918 GiB
Execution Times
Total time …………. 00:44.05
CPU time …………… 00:36.88
Swap time ………….. 00:07.12
Swap transfer rate ….. 2329.464 MiB/s Performance Indices
Total performance …… 10679
CPU performance …….. 10264
Swap performance ……. 12902
*******************************************************************************
My PI rig is an 8 year old, ex-lease server and cost me less than $700 AUD (including the $125 I spent putting a GTX 1080 in it, and the $150 1tb nVME that all my active data and swap files are on)
The rig is not without its deficiencies, but there is a big misconception around high performing pixinsight rigs being incredibly expensive…
The thing this benchmark does not show, which has been mentioned above, is performance of things like WBPP.
While my CPU score here was 10391 (not bad for a 8 year old CPU), with 28 physical cores and 56 threads, WBPP for me takes next to no time compared to a lot of other rigs.
Last week I collected ~400 subs with my IMX-294, with 50x darks, 50x flats, 50x flat darks and 50x bias frames, including local normalisation, image solving 2x drizzle and autocrops it took under an hour. When the rig can operate on 50 images simultaneously, the processes in WBPP become incredibly fast… Things like BXT/NXT/SXT all run in a matter of seconds as well, although the 1080 is a long way from a 4090 etc, its still PLENTY fast enough for PI work.
I could probably spend 3x what I spent on this rig and get a marginal improvement in CPU and swap performance, but I don't see the value, when that same dollar figure could go into another mount so I can run both my scopes at the same time… or a better camera…
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
One thing I do want to make clear, is that if you have a major pixinsight update, where you have to download the latest full version, you will need to set up the swap folders again, as for some reason it re sets them to default, which is really anoying..standard PI updater is not a problem…
Thanks for all the comments and replies, nice to see it has helped most of you…👍🏻
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
John Hayes:
As you can see, there is no meaningful difference. Also note that PI is identifying the M2 ARM chip as "GenuineIntell", which is not right...it's an Apple chip. My machine has a 2TB drive with 64GB of ram (as correctly ID'd by PI).
My conclusion is that this trick does not work on the ARM equipped Apple machines.
John Hey John, Hope all is well. The MacOS build of PixInsight uses x86 emulation and as such will not be optimized by this or other procedures commonly used to "speed up" PixInsight. The true fix for this is for the PI team to release an Apple Silicon optimized build of the software. I think there were some issues Rob (pfile) mentioned they were facing with the underlying platform that was slowing progress on this. At any rate, these tricks are not likely going to be effective on Macs due to this. Since you are a great scientist, and thus love doing some A/B testing, you should grab the MacOS optimized version of Astro Pixel Processor. While its interface can take a few steps to get familiar with, it does run the same effective suite of processes that WBPP does. I think you would find the test of one set of the same data, run through both of them to be quite interesting to see. This is not to say that you should use APP instead, rather it is to show how much more efficient PI can be if they were to release the Apple Silicon build. FWIW, I wrote about this exact topic (SWAP DIR threads) 7 years ago on CN: https://www.cloudynights.com/topic/563965-disappointing-performance-of-pixinsight-on-my-laptop/?p=7750668-Bill
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
John Hayes:
Interesting. I tried this on my MacBook Pro M2 with a 2TB SSD and it made essentially zero difference.
It would be nice if, when reporting results, participants would provide information about their hardware.
John John (and all other Mac users), here some data from my setups: MacPro (2019), 16-core Intel Xeon, 160GB RAM: - 8 extra swap drives on Macintosh HD: no improvement - 8 extra swap drives over 2 external SSDs (NVME, similar speeds as internal HD): 15% improvement - 8 extra swap drives over 8 RAM disks: 40% improvement MacBook Pro, M2 Max, 64GB RAM: - 8 extra swap drives on Macintosh HD: 20% improvement - 8 extra swap drives over 8 RAM disks: 50% improvement Note that the default installation of PI on the MacPro has 4 default swap drives installed (those var/folders.....), whereas on the MacBook Pro, only one default swap drive is installed. That probably explains why the improvements on the MacBook are a bit bigger than on the MacPro. So on the Mac it appears that serious improvements (40%) can be achieved when using RAM disks. Additional swap drives on the internal HD have no/negligible effect. RAM disks can be installed by software such as RAMDiskCreator. I've used this in the past quite a bit, but since RAM disks disappear on restart of the computer, they became over time more of an annoyance than a benefit. So I stopped using them. A much more (call it huge) difference is the use of FBPP vs WBPP. It has now become my default tool to start with. Note, the comparisons above are on Swap Performance, which is only one part of total performance. Willem Jan
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Willem Jan Drijfhout:
John Hayes:
Interesting. I tried this on my MacBook Pro M2 with a 2TB SSD and it made essentially zero difference.
It would be nice if, when reporting results, participants would provide information about their hardware.
John
...
Note, the comparisons above are on Swap Performance, which is only one part of total performance.
Willem Jan Absolutely - swap performance is only part of the total performance. Lots of CPU cores/threads make all the difference in the world. FBPP does indeed make a SIGNIFICANT difference, if the features of WBPP aren't required for your specific data. I can't use FBPP on account of the fact that my data is significantly undersampled at anywhere between 2.3"/px to 3.5"/px, so I need to use drizzle (anywhere from 2x to 4x). I also let WBPP do my image solving, localised normalisation. I'm on a powerful enough machine, and I'm never in such a dramatic hurry to get my data integrated that I would forego those steps in WBPP, however the improvement that I get in PI across the board from adding multiple swap directories in either a nvme drive, or as you say, a 32Gb RAM disk is significant enough to still be worth doing. I might look at upgrading from 64GB of RAM to 256GB of RAM so I can allocate 128GB or more to a RAM disk for PI Swap....RAM for my old 2016 dual xeon rig is pretty cheap afterall.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
I am somewhat surprised by the results here. It looks like the swap performance will often dramatically improve, however that usually only seems to affect the TOTAL TIME by a few seconds, maybe 10 seconds or so.
Does that mean that most of these systems are CPU bound when running the benchmark?
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
I am somewhat surprised by the results here. It looks like the swap performance will often dramatically improve, however that usually only seems to affect the TOTAL TIME by a few seconds, maybe 10 seconds or so.
Does that mean that most of these systems are CPU bound when running the benchmark? The CPU will just run at its fastest speed anyway during the benchmark, and will not change no matter how many swap folders you use, all that changes it the speed of the swap, and the amount and speed of transefer to and from the swap, so when the overall time is faster it purely down to faster swap time, my particular system which I showed in the video, was using 4 swap folders on 3 drives totals 12 folders, and this gave me a total benchmark test time of time of 59 seconds, (down from 1.5 mins with default settings) but I have just changed it to 12 swap folders on my main C drive and 4 on the second D drive and decided not to use the third SSD drive, and it’s come down considerably more, to 27 seconds total, but the CPU time was the same on all tests no matter how many swap folders or where they were placed…
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
I have a CPU with 16 threads, and it seems that 16 swap folders in a certain configuration are the optimal settings…after much more testing…
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
I suspect the benchmark takes a single image and runs a couple of processes on it. Not very I/O heavy. A large stack using WBPP would have a lot more I/O and even a 10% improvement in swap speed from this benchmark would I expect have a much larger impact overall. It’s worth doing that comparison.
The new Apple Silicon with its unified memory and high bandwidth to storage is already so fast that I’m not surprised the results on it are not as impressive as a PC with separate memory and storage on a shared bus.
Tom.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Dark Matters Astrophotography:
The true fix for this is for the PI team to release an Apple Silicon optimized build of the software. I think there were some issues Rob (pfile) mentioned they were facing with the underlying platform that was slowing progress on this. At any rate, these tricks are not likely going to be effective on Macs due to this. yeah - the problem is that the JavaScript interpreter in PI (which interprets PI scripts such as WBPP etc.) is pretty old - i think it's SpiderMonkey. apparently there's no SpiderMonkey sources that are compatible with ARM macs, and juan did mention something one time about apple having a prohibition on JIT ("Just-In-Time") compilers, but my crude understanding is that's a prohibition for iOS and probably also mac apps distributed thru the mac app store. but i don't see why that's immediately a hinderance for ARM PI on macs. it's probably more that SpiderMonkey is fully deprecated and no one wants to do the work to make it compatible with ARM macosx. it turns out that this is also a blocker for windows PI on ARM hardware. the implication of this is that juan would have to adopt a new javascript interpreter, and the behind the scenes work is, well, a lot of difficult and thankless work. but the problem is that someday apple is going to stop supporting Rosetta2 and when that happens, no more PI (if you upgrade your mac to the latest OS, anyway.) Tom Dinneen:
I suspect the benchmark takes a single image and runs a couple of processes on it. Not very I/O heavy. that is correct. it also calculates the disk IO time by taking the process wall time (as reported by the process itself) and subtracting it from the wall time starting and ending with the process call. thus all overheads that are not process related are assigned to IO, which is not actually correct. in general optimizing your system for a synthetic benchmark vs. real workloads is not the best idea. like a lot of others in this thread i think people put too much stock in the benchmark numbers. i do think they are useful for comparing systems broadly, but tweaking like crazy to make the benchmark faster is wasted work. a good example is the trend (thankfully over) of people putting their PI swap on RAMDisk. this is fine if you process a couple of images and quit PI. but if you run large projects with a large sensor, there's a good chance you'll fill up that RAMDisk pretty quickly. and guess what, PI isn't so graceful about a full swap disk. it might become impossible to save your project and PI itself could become somewhat unstable. so IMO it's not a great idea to trade the flexibility of a large swap area for the benchmark gains when the swap area is on a RAMDisk. to be sure, almost every modern OS uses free memory to cache filesystem objects, so if you are hitting the same swap files over and over again they are likely coming out of main memory anyway.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Tom Dinneen:
I suspect the benchmark takes a single image and runs a couple of processes on it. Not very I/O heavy. A large stack using WBPP would have a lot more I/O and even a 10% improvement in swap speed from this benchmark would I expect have a much larger impact overall. It’s worth doing that comparison. PI swap is different than the system swap which WBPP will use in the case of system memory exhaustion when dealing with large stacks.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Dark Matters Astrophotography:
The true fix for this is for the PI team to release an Apple Silicon optimized build of the software. I think there were some issues Rob (pfile) mentioned they were facing with the underlying platform that was slowing progress on this. At any rate, these tricks are not likely going to be effective on Macs due to this.
yeah - the problem is that the JavaScript interpreter in PI (which interprets PI scripts such as WBPP etc.) is pretty old - i think it's SpiderMonkey. apparently there's no SpiderMonkey sources that are compatible with ARM macs, and juan did mention something one time about apple having a prohibition on JIT ("Just-In-Time") compilers, but my crude understanding is that's a prohibition for iOS and probably also mac apps distributed thru the mac app store. but i don't see why that's immediately a hinderance for ARM PI on macs. it's probably more that SpiderMonkey is fully deprecated and no one wants to do the work to make it compatible with ARM macosx.
it turns out that this is also a blocker for windows PI on ARM hardware.
the implication of this is that juan would have to adopt a new javascript interpreter, and the behind the scenes work is, well, a lot of difficult and thankless work. but the problem is that someday apple is going to stop supporting Rosetta2 and when that happens, no more PI (if you upgrade your mac to the latest OS, anyway.)
Tom Dinneen:
I suspect the benchmark takes a single image and runs a couple of processes on it. Not very I/O heavy.
that is correct. it also calculates the disk IO time by taking the process wall time (as reported by the process itself) and subtracting it from the wall time starting and ending with the process call. thus all overheads that are not process related are assigned to IO, which is not actually correct.
in general optimizing your system for a synthetic benchmark vs. real workloads is not the best idea. like a lot of others in this thread i think people put too much stock in the benchmark numbers. i do think they are useful for comparing systems broadly, but tweaking like crazy to make the benchmark faster is wasted work. a good example is the trend (thankfully over) of people putting their PI swap on RAMDisk. this is fine if you process a couple of images and quit PI. but if you run large projects with a large sensor, there's a good chance you'll fill up that RAMDisk pretty quickly. and guess what, PI isn't so graceful about a full swap disk. it might become impossible to save your project and PI itself could become somewhat unstable. so IMO it's not a great idea to trade the flexibility of a large swap area for the benchmark gains when the swap area is on a RAMDisk. to be sure, almost every modern OS uses free memory to cache filesystem objects, so if you are hitting the same swap files over and over again they are likely coming out of main memory anyway.
I'm starting to wonder about the utility of the current PI benchmark. I see people chasing improvements on the level of seconds, maybe 10-20 seconds nowadays (when a lot of systems are already under the 1 minute mark for the entire benchmark.) The longest time-sink for me is pre-processing, not post-processing, and MOST of the time spent in post is usually me manually evaluating results and deciding whether I like them or not, then either re-running a process (which is usually on the level of noise relative to my evaluation times) or moving onto the next one. It would be far more interesting and utilitarian, if PI had a benchmark that tested the pre-process flow, or at least the critical parts of it. Calibration, Registration, Integration.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
It would be far more interesting and utilitarian, if PI had a benchmark that tested the pre-process flow, or at least the critical parts of it. Calibration, Registration, Integration. Agreed. I'd add SubFrameSelector to that list as well. That and Image Integration are where I often spend a lot of time waiting for the process to complete. John
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Die Launische Diva:
Tom Dinneen:
I suspect the benchmark takes a single image and runs a couple of processes on it. Not very I/O heavy. A large stack using WBPP would have a lot more I/O and even a 10% improvement in swap speed from this benchmark would I expect have a much larger impact overall. It’s worth doing that comparison.
PI swap is different than the system swap which WBPP will use in the case of system memory exhaustion when dealing with large stacks. Sure, but whether it's the OS swapping memory or PI saving large temporary files it's all I/O to disk. Any improvement there should have more impact on operations that require a lot more I/O that this simple benchmark. I'm on a Mac Studio M2 Max so emulating via Rosetta. My swap score is still 3.87 seconds. Speeding that up by 10% will bring me down to 3.5 seconds or so. Hardly noticeably for this test but that might translate to 10 mins for a large integration. That was my badly worded point. As Bill mentioned APP on Apple Silicon screams. I used to jump between it and WBPP when I had an Intel Mac but now I just use APP for pre-processing. It's a 20-30 min versus a 2-3 hrs difference. They've added graphs as well to help prune but I still use Blink and SubFrameSelector for that. Maybe SetiAstro who's on a run lately can grace us with a BenchXTerminator script ;-)
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
AstroShed:
I have a CPU with 16 threads, and it seems that 16 swap folders in a certain configuration are the optimal settings…after much more testing… So anecdotealy, that means I need 56 swap folders... Sigh... haha
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
John Hayes:
Jon Rista:
It would be far more interesting and utilitarian, if PI had a benchmark that tested the pre-process flow, or at least the critical parts of it. Calibration, Registration, Integration.
Agreed. I'd add SubFrameSelector to that list as well. That and Image Integration are where I often spend a lot of time waiting for the process to complete.
John Agree with both of you on this. The interesting thing, and I mentioned this before and it is worth mentioning again -- is that you can largely see the difference on the Mac Silicon platform by using PI's WBPP on a Mac and APP's Mac Silicon optimized build of their software. While I get that these are two completely different products, and people may not wish to switch (which I am not advocating for at all) seeing the difference first hand, is quite amazing to witness with the same set of data in an A/B test. I wonder if folks are actually aware of how significantly overpowered PI is in the market on the Linux platform. It roasts everything else (including APP) on Linux. It is not even a contest at all, and it just makes you wish that the other two supported platforms were optimized at the same level. If someone really wants some serious PI horsepower, all you need to do is take the exact same hardware you use now, and just put a Linux partition on it and run PI there. If you have not done this test before (and I do not mean the benchmark itself, although I believe that too is also a huge change) I strongly suggest you try it. I even took the Windows machine I use for PI installed a Linux VM on it (with Windows as the VM host) and the VM grossly outperformed the host, largely because of how optimized PI is on Linux. -Bill
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Dark Matters Astrophotography:
John Hayes:
Jon Rista:
It would be far more interesting and utilitarian, if PI had a benchmark that tested the pre-process flow, or at least the critical parts of it. Calibration, Registration, Integration.
Agreed. I'd add SubFrameSelector to that list as well. That and Image Integration are where I often spend a lot of time waiting for the process to complete.
John
Agree with both of you on this.
The interesting thing, and I mentioned this before and it is worth mentioning again -- is that you can largely see the difference on the Mac Silicon platform by using PI's WBPP on a Mac and APP's Mac Silicon optimized build of their software. While I get that these are two completely different products, and people may not wish to switch (which I am not advocating for at all) seeing the difference first hand, is quite amazing to witness with the same set of data in an A/B test.
I wonder if folks are actually aware of how significantly overpowered PI is in the market on the Linux platform. It roasts everything else (including APP) on Linux. It is not even a contest at all, and it just makes you wish that the other two supported platforms were optimized at the same level. If someone really wants some serious PI horsepower, all you need to do is take the exact same hardware you use now, and just put a Linux partition on it and run PI there. If you have not done this test before (and I do not mean the benchmark itself, although I believe that too is also a huge change) I strongly suggest you try it.
I even took the Windows machine I use for PI installed a Linux VM on it (with Windows as the VM host) and the VM grossly outperformed the host, largely because of how optimized PI is on Linux.
-Bill Oh, so now you have some Interest in this thread, after roasting me for even starting it one here….unbelievable….🤷🏼♂️
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
This topic was closed by a moderator.