That's what I was going to say, planetary imagers do thousands of 8-bit images at pretty high gains, they don't end up with crazy amounts of read noise.
Of course signal is pretty high to begin with and the background is rendered as (and supposed to be) completely black, without any dust or glow.
Most of the discussion about read noise vs sky background noise is relevant only to the sky background (and maybe the faintest parts of a DSO). Brighter regions are much less impacted by either. Technically speaking, they DO end up with crazy amounts of read noise. ;) I mean, the math would indicate as much, for sure. SSO images are also usually not calibrated, so you are also having to deal with massive growth in FPN as well, which would rapidly overcome the limitations from read noise were it not for the effective dithering. But planetary stacking is going to face the same growth in read noise with sub count as any other stacked imaging. Stack 10000 frames, you'll have 10000 units of read noise. Remember though that the basic math we usually use in theory with this stuff, excludes the average step. We integrate the data with simple formulas like this: (Sobj * Csubs)/SQRT(Csubs * (Sobj + Sdark + Nread^2)) This makes it easy to see how all the individual noise terms compound. But, with averaged stacking, the above is essentially missing that averaging step, which basically gives us: Sobj/(SQRT(Csubs * (Sobj + Sdark + Nread^2)) / Csubs) This is why we can say that stacking "averages DOWN" noise....in total. We essentially hold signal strength the same, and average out the noise terms so that relative to that absolute signal strength, the noise scale gets smaller. Planetary images are indeed going to have a lot more units of read noise (Csubs) than most DSO images. The thing with planetary is shot noise from the object is usually WAY beyond the criteria we use for DSO. Where we often aim for 10xRN^2 with DSO, you are easily getting many, many times that with SSO images (even if you aim for just a middling signal level, that is still thousands of electrons per sub vs. just tens of electrons common in DSO subs). Shot noise will utterly dominate in the SSO domain, until FPN becomes the limiting factor. The sheer strength of the signal is why its possible to get away with 8-bit data and stacking thousands of frames. I suspect the only reason FPN doesn't become a limiting factor within a couple thousand frames is because with SSO you are tracking a moving object and that effectively results in highly dithered frames.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
… but you end up with a LOT of RON in SSO imagery and if you were to look at the faint tail of the signal you'll be horrified. You can get away because you have massively more signal than you would otherwise have in any likely DSO scenario. So the comparison is moot. And the stacked frame histogram isn't the same either. Effective DR is conversely very shallow when compared with DSO imagery nor it needs so much latitude between the shadows and the highlights because for SSO everything is in the highlights.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
I used to do long-exposure deep sky astrophotography, but now I do mostly short-exposure astrophotography. Exceptions are when I photograph star trails and the occasional Aurora. On this site, I'm probably in the minority, because I use camera lenses and a DSLR on a fixed mount. Although I sacrificed serious deep sky imaging in general, I found that short exposures are really good for bringing out star colours. It also highly depends on how you process your images. For example, I found that modest contrast enhancement plus moderate-to-high saturation brings out star colours of brighter stars really well. High contrast and brightness enhancement brings out the star colours of fainter stars, but the brighter stars appear mostly white. Here, I combined both methods to get the best of both: 
Gamma CassiopeiaeFrom my experience, if your goal is to capture the absolute faintest features, do long exposures. You can take shorter exposures to capture the colours of the brightest features and then combine the two results for a more complete composite to get the best of both. Composites are really good in bringing out what you normally can't get in just one stack of exposures. Here's a short-exposure composite I did of the Northern Coalsack area: 
CygnusIt all depends on what you want to capture. My goal is to capture rich star fields with high contrast star colours and short-exposure astrophotography is really good for that.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
John Hayes:
Tim Hawkes:
Thanks for your reply and the learning. I certainly didn't know most of that. One further question though. Surely part of the point of Blur Xt deconvolution is that it can beat the seeing - always provided that your sampling rate supports a higher resolution. So in a short frame you get atmosphere -distorted star PSFs but distortions that are at least distorted in a reasonably consistent way within any given region of the frame and over a short time. BlurXt (I presume) iteratively calculates the correct local cmpensatory correction and then applies it. So the question is that while it is clearly always better to start from a near perfect image and to then apply deconvolution to -- in my experience at least - BlurXt takes you a long way even when the star shapes are not perfect . In my M51 picture above average Eccentricity was up at maybe 0.55 prior to correction and deconvolution. Maybe consistency of blur is more important to the end product than lack of blur as a starting point to apply deconvolution to? Tim
Russ had a genius idea for BXT and he had to solve a lot of the details to make it work as well as it does. At a high level, the concept is actually pretty straight forward. I should add here that Russ hasn't given me any inside information but here's my guess about how he might have implemented it. It is simply a neural network that is loaded with NxN patches of Hubble images that have been mathematically blurred (probably with just a Gaussian blur function). N might be a value that ranges from 32 to maybe 512--depending on how Russ chose to set it up. There might be anywhere from 300,000 to 1,000,000 samples loaded into the training set, which is then trained using the original blurred data to find the best match out of all of the samples. The training can include a lot of different parameters including the amount of blurring, asymmetry in the blurring (smear), and noise levels. When you sharpen your own image, the data is subdivided into NxN patches so that each patch in your data can be identified with the "mostly likely" fit to a solution. Once identified, the information in that patch is replaced with the original image data that created the best-fit blurred data. Note that this is not the same as simply inserting Hubble images directly into your image. The image patches are small enough that the Hubble data serves mostly as a way of supplying a nearly limitless source of "sharpened patterns" that can be used to show what your more blurry data might look like without the blurring mechanism. I believe that the process for de-blurring the stars is similar but it may be different enough that it runs as a separate process from the structure sharpening. That's something that Russ would have to address. I could imagine that the star correction NN could be loaded with mathematically computed Moffat data that has been filtered through a range of aberrations as well as image translations. One of the tricky parts to all of this is to get everything normalized properly so that the results all fit together seamlessly.
So nothing in BXT is like the traditional deconvolution process that requires a PSF kernel. BXT has the ability to solve for the seeing conditions, but Russ didn't choose to work that into the solution. Regardless, BXT doesn't have to know anything about the seeing to work well. It just uses mathematically blurred data and since the process is applied patch-wise across the field, it can effectively correct for field aberrations (that vary with position) as well as for motion blur.
John Hi John, The speculation that you provided as to how BXT might work versus a neural net library of tiny subfragments was very interesting and has been sort of lurking in the back of mind for a week or so since it raised a question that I wasn't easily able to dismiss. Perhaps you wil be able to? If the process of BXT sharpening is indeed to sequentially scan through mini-segments the input image and then replace the contents within each with the probable best candidate from a neural net library of "micro-features" (after accounting for the blurring) thent might that imply - beyond some threshold level of input quality- what you then stand to get out with any further increases in the input quality may become more and more marginal ? i.e. once a level of say 90-95% of correct neural replacements have been made then there might be diminishing returns? An input image only has to be good enough to trigger the correct replacements - and once nearly all correct there can be nothing much further to gain? I've only come back to this point because I am still surprised by the quality of the M51 image that I was finally able to get to using RC BlurXT even despite the fact that virtually all of the images that went into making it suffered from -as you correctly diagnosed - significant RA motion blur. I compared the detail at the core of my final M51 image with the publicly available 2005 HST image and it does seem to show most of the features correctly as far as I can see (except of course all the HA features). I suppose that what I am asking is "How much further room for improvement can there realistically be? and if the input images had completely lacked motion blur how much further details could have become evident? Of course it may simply be that the NN library of micro-features is just more fine-grained than I am imagining and can add detail well below the 1 arcsec level - in which case even the finest subtleties of HST images woiuld come in range with better inputs? Anyway thanks for any thoughts on this from you or anyone else . I don't know how BlurXt actually works and so may well have it all wrong and always happy to be educated . Tim  |
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
John Hayes
I think I would be rather disappointed if your description of what is happening under the hood with BlurXTerminator is correct. Then calling it "deconvolution" would not really be valid. It would be more like hiring some artist to improve your images using HST imagery as a guide.
Bob
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
John Hayes
I think I would be rather disappointed if your description of what is happening under the hood with BlurXTerminator is correct. Then calling it "deconvolution" would not really be valid. It would be more like hiring some artist to improve your images using HST imagery as a guide.
Bob Has anyone asked Russ how it works?
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
John Hayes
I think I would be rather disappointed if your description of what is happening under the hood with BlurXTerminator is correct. Then calling it "deconvolution" would not really be valid. It would be more like hiring some artist to improve your images using HST imagery as a guide.
Bob
Has anyone asked Russ how it works? I have in response to Russ’s short white paper on the math of Blur Exterminator. https://www.rc-astro.com/the-mathematics-of-blurxterminator/I asked some clarifying and probing questions to get a better idea about where deconvolution happens versus an AI based selection of data or paremeters. He declined to answer, saying that it would get too much into the proprietary nature of the algorithm. That was here: https://www.cloudynights.com/topic/903373-blurxterminator-20/page-11#entry13180765I lieu of that I did some testing on the algorithm to shed some light on one of my questions with my results here: https://www.cloudynights.com/topic/908264-doing-some-blurxterminator-20-ai-4-experiments/- Steven
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Steven Miller:
Jon Rista:
John Hayes
I think I would be rather disappointed if your description of what is happening under the hood with BlurXTerminator is correct. Then calling it "deconvolution" would not really be valid. It would be more like hiring some artist to improve your images using HST imagery as a guide.
Bob
Has anyone asked Russ how it works?
I have in response to Russ’s short white paper on the math of Blur Exterminator.
https://www.rc-astro.com/the-mathematics-of-blurxterminator/
I asked some clarifying and probing questions to get a better idea about where deconvolution happens versus an AI based selection of data or paremeters. He declined to answer, saying that it would get too much into the proprietary nature of the algorithm. That was here:
https://www.cloudynights.com/topic/903373-blurxterminator-20/page-11#entry13180765
I lieu of that I did some testing on the algorithm to shed some light on one of my questions with my results here:
https://www.cloudynights.com/topic/908264-doing-some-blurxterminator-20-ai-4-experiments/
- Steven Thanks for the links! I totally understand Russ's desire to keep his super secret sauce super secret. It is his business after all. His tools are pretty amazing, and I respect his goal of protecting his critical IP. The white paper is very enlightening. His approach is very interesting, and I think I understand now why the results can be so good...he isn't aiming for perfection, but instead aiming for a smaller PSF, g', to produce a better (but not perfect, i.e. zero-width PSF) image, h'. Kind of genius, actually. I can also understand why he says this isn't necessarily deconvolution... Technically speaking, these days, neural networks generated from ML are so complex, we can no longer decipher or understand them. So it may well be that we simply cannot know exactly how the AI process takes f (or rather, f+g+n) and produces h'. HOWEVER it does it, the ultimate goal was actually to reduce the error, e... HOWEVER it happens, by minimizing e, Russ's product is able to arrive at a fairly optimal result (one in which the stars are NOT all single-pixel points of light, which would be incredibly boring (!!) but instead produces a natural result with a meaningful diversity of star sizes that make sense.) Since the NN was designed to minimize the error, e, I am not so sure that there is any kind of data replacement going on. We can't know exactly what the NN is doing, it would be too complex to decipher. It may be that some of the training data had the stars replaced with more optimal exemplars, or that the source data itself was more optimal (Hubble or other carefully sourced and curated scientific data). Since the NN was produced with an algorithm who's purpose was to minimize the error between h' vs. f, then that's what the network will do. I don't think that requires replacing stars with other stars... The network should be able to directly produce the output image from the source image without any replacement.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Steven Miller:
Jon Rista:
John Hayes
I think I would be rather disappointed if your description of what is happening under the hood with BlurXTerminator is correct. Then calling it "deconvolution" would not really be valid. It would be more like hiring some artist to improve your images using HST imagery as a guide.
Bob
Has anyone asked Russ how it works?
I have in response to Russ’s short white paper on the math of Blur Exterminator.
https://www.rc-astro.com/the-mathematics-of-blurxterminator/
I asked some clarifying and probing questions to get a better idea about where deconvolution happens versus an AI based selection of data or paremeters. He declined to answer, saying that it would get too much into the proprietary nature of the algorithm. That was here:
https://www.cloudynights.com/topic/903373-blurxterminator-20/page-11#entry13180765
I lieu of that I did some testing on the algorithm to shed some light on one of my questions with my results here:
https://www.cloudynights.com/topic/908264-doing-some-blurxterminator-20-ai-4-experiments/
- Steven Thanks so much for asking the questions and posting this Steven! It clarifies a good deal --- but it is a deep subject and will certainly take a while to mull over and absorb :-). One sentence about the tile locality of the PSF estimates struck me .."The PSF for each tile is instead inferred from the stars present in that tile, stars being excellent approximations of point sources and therefore copies of the PSF with varying brightness and color." Like you I also carried out a few experiments to try and better understand what the software is doing. One experiment was to better understand what "correct only" was actually doing. I started with 620 x 10s calibrated frames of Messier 108. FWHM varied from about 4 - 6 pixels (at 0.406 arcsec/ pixel) and the average Eccentricity was about 0.54 (orientated approx along the RA axis - i.e. RA blur issue) . Frames were processed alternatively -- 1) Just registering and integrating the frames in the normal PI default way 2) Running Blur Exterminator "Correct only" on each of the frames prior to registration and then integration Integration 1) was av. FWHM 4.72. pixel Eccen. 0.545 and 2) was av. FWHM 4.56 pixel Eccen. 0.450. Both integrations were then further processed with BlurXt correction only then followed by 0.9X of non-stellar sharpening (no star reduction). Following this BlurXT post-processing 1) yielded apparent av. FWHM 3.52 and Eccen. 0.37 while 2) was av. FWHM 3.37 and Eccen. 0.38 - so similar within error The most significant observation was that the non-stellar sharpening details looked identical in the two processed images. This was despite the fact that by pre-running the BlurXT star correction prior to registration I must have broken any link between stellar PSFs Eccentricity and non stellar parts of the image ?I think that this means that however the non-stellar sharpening process is working it does not really rely on local estimates of the stellar PSFs Eccentricity in any way? In integrated images 1) and 2) the stellar PSFs indicate significantly different Eccentricity values. Yet the non-stellar sharpening from running BXT appears identical (Left image shows M108 detail of 1) without pre-application of Blur XT star correction prior to registration and the right image , 2), with. The images were post-processed in BlurExterminator identically. 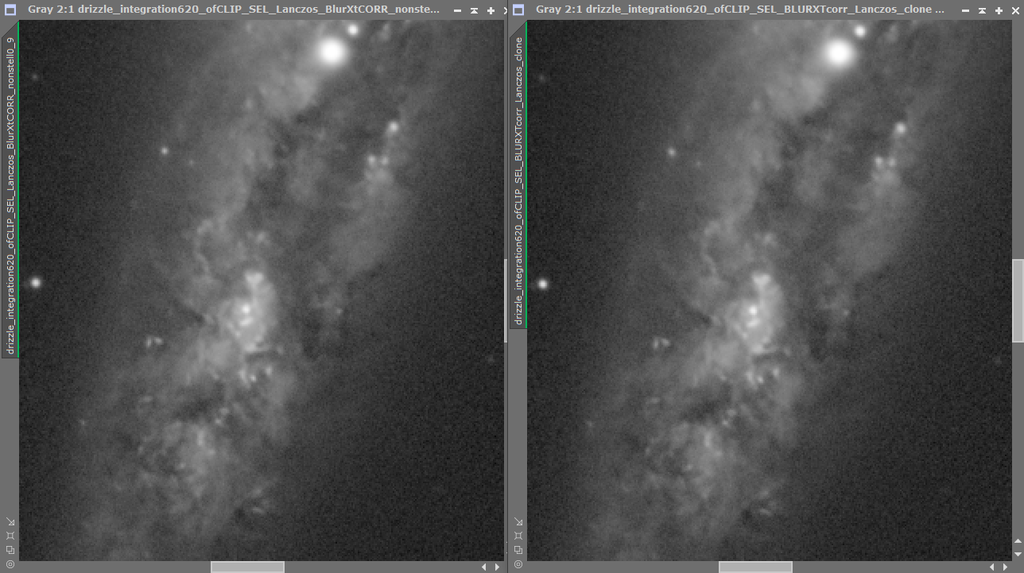 PS. Just adding the other perhaps more obvious expt which was to try out non-stellar sharpening on starless images, This shows that PSF diameter does matter for non-stellar sharpening (which is obviously why there is a manual box that allows you to specify PSF diameter) --which fits with RC's description - but it seems not PSF Eccentricity. So provided that you specify the correct PSF (i.e of the stars that you removed) BlurXT non-stellar sharpening works fine on images with no stars in them. I suspect that the AI sharpening process needs input on the size of the PSF that it should minimize to as part of the target for iteration but has it's own internal model of all the various blurring effects that could alter the apparent shape of this PSF and so does not really need to take this information from actual measurements of the stellar PSFs in the image? This probably explains why it has does so well in deblurring images even where the star shapes aren't round? Tim 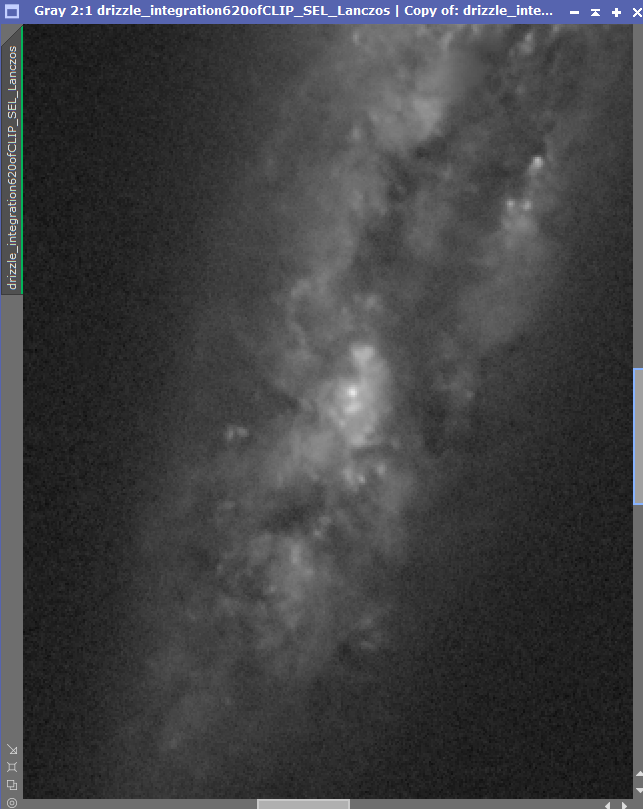 |
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Tim Hawkes:
This may be compression artifacts, not sure...but, there seems to be something strange with your noise profile. It doesn't look gaussian/poisson. Was there any other processing done to this data before BXT was applied?
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
Tim Hawkes:
This may be compression artifacts, not sure...but, there seems to be something strange with your noise profile. It doesn't look gaussian/poisson. Was there any other processing done to this data before BXT was applied? Hi Jon. It is not processed at all (apart from by BXT) --it is just noisy and also a tiny field shown large -- looking at the statistics for the entire frame (of which this is just a small crop of) the profile is more or less Poisson with the std deviation about the sqrt of the mean. It is noisy data ..but I didn't want to assume that you could combine data from different nights (which would have increased SNR) and then use BXT afterwards? Non-commutative process? So the data are all from a single night and a bit sparse. Also I doubtless overdid the non-stellar sharpening. However - again - even in this highly imperfect case - when you compare the sharpened images with HST images BlurXt doesn't seem to be making stuff up. I haven't enough data for a finished image of this object but this is with more data and proper processing v publically available HST data (a very small part only of M108). Again I am very impressed with what BXT is doing even if it is rather opaque how the AI works.  |
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Tim Hawkes:
Jon Rista:
Tim Hawkes:
This may be compression artifacts, not sure...but, there seems to be something strange with your noise profile. It doesn't look gaussian/poisson. Was there any other processing done to this data before BXT was applied?
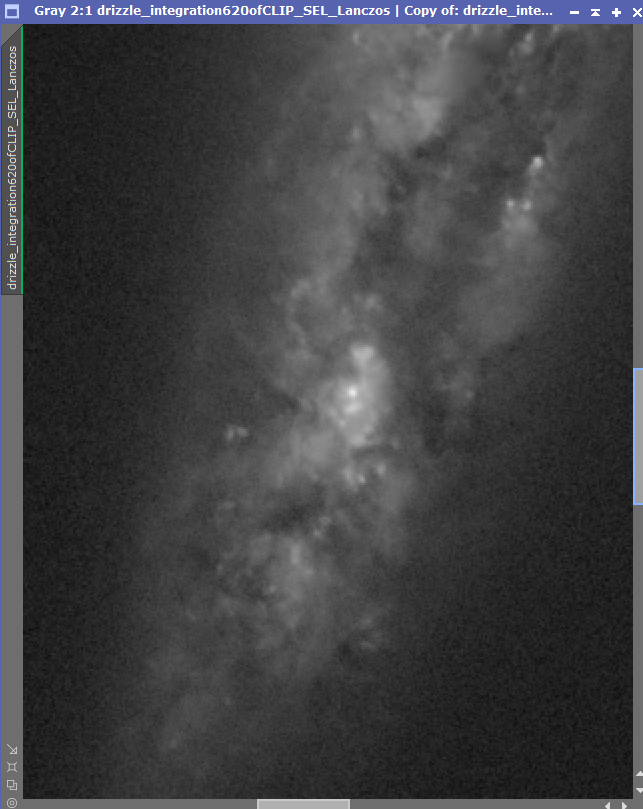
Hi Jon. It is not processed at all (apart from by BXT) --it is just noisy and also a tiny field shown large -- looking at the statistics for the entire frame (of which this is just a small crop of) the profile is more or less Poisson with the std deviation about the sqrt of the mean. It is noisy data ..but I didn't want to assume that you could combine data from different nights (which would have increased SNR) and then use BXT afterwards? Non-commutative process? So the data are all from a single night and a bit sparse. Also I doubtless overdid the non-stellar sharpening. However - again - even in this highly imperfect case - when you compare the sharpened images with HST images BlurXt doesn't seem to be making stuff up. I haven't enough data for a finished image of this object but this is with more data and proper processing v publically available HST data (a very small part only of M108). Again I am very impressed with what BXT is doing even if it is rather opaque how the AI works.
In the closer crops, there is a fine-grained characteristic to the noise that looks odd. Its some kind of horizontal micro structuring? Again, it could just be the result of compression, but it makes me wonder if, given it has some patterned structure, if it might be affecting BXT? FWIW, I've always done BXT on multi-night data. In the end, the integration is a statistical result from all the various frames, each of which are scaled and redistributed to be optimally compatible with each other. BXT seems to work just fine on data that comes from a dozen or more different nights. BXT doesn't know about the individual frame statistics...it only knows about the final integration. Opaqueness is the thing with AI now. Modern neural networks are insanely complex now. I've done a lot of scrutinizing how BXT works by close up pixel peeping and contrasting the results in PI by undoing and redoing various previews. One of the things that really amazes me, is with noisy data, at least poisson noise, is when a star is corrected, the noise around it does not seem to change. Even noise within the halo, the underlying signal may drop, but the noise itself doesn't really seem to change. That fine-grained accuracy is one of the things that blows me away about AI, or at least about BXT itself. The neural network is a system who's sole purpose is to transform poorly convolved data, into more optimally convolved data. That optimization occurs at many scales, it seems, right down to the very fine grained, subtle noise characteristics. Quite impressive. (FWIW, I am not one who likes to eliminate/obliterate noise...I like to have a bit of fine grained, low profile noise in my final images. So, the resulting noise after BXT and NXT is actually really important to me.)
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
Tim Hawkes:
Jon Rista:
Tim Hawkes:
This may be compression artifacts, not sure...but, there seems to be something strange with your noise profile. It doesn't look gaussian/poisson. Was there any other processing done to this data before BXT was applied?
Hi Jon. It is not processed at all (apart from by BXT) --it is just noisy and also a tiny field shown large -- looking at the statistics for the entire frame (of which this is just a small crop of) the profile is more or less Poisson with the std deviation about the sqrt of the mean. It is noisy data ..but I didn't want to assume that you could combine data from different nights (which would have increased SNR) and then use BXT afterwards? Non-commutative process? So the data are all from a single night and a bit sparse. Also I doubtless overdid the non-stellar sharpening. However - again - even in this highly imperfect case - when you compare the sharpened images with HST images BlurXt doesn't seem to be making stuff up. I haven't enough data for a finished image of this object but this is with more data and proper processing v publically available HST data (a very small part only of M108). Again I am very impressed with what BXT is doing even if it is rather opaque how the AI works.
In the closer crops, there is a fine-grained characteristic to the noise that looks odd. Its some kind of horizontal micro structuring? Again, it could just be the result of compression, but it makes me wonder if, given it has some patterned structure, if it might be affecting BXT?
FWIW, I've always done BXT on multi-night data. In the end, the integration is a statistical result from all the various frames, each of which are scaled and redistributed to be optimally compatible with each other. BXT seems to work just fine on data that comes from a dozen or more different nights. BXT doesn't know about the individual frame statistics...it only knows about the final integration.
Opaqueness is the thing with AI now. Modern neural networks are insanely complex now. I've done a lot of scrutinizing how BXT works by close up pixel peeping and contrasting the results in PI by undoing and redoing various previews. One of the things that really amazes me, is with noisy data, at least poisson noise, is when a star is corrected, the noise around it does not seem to change. Even noise within the halo, the underlying signal may drop, but the noise itself doesn't really seem to change. That fine-grained accuracy is one of the things that blows me away about AI, or at least about BXT itself. The neural network is a system who's sole purpose is to transform poorly convolved data, into more optimally convolved data. That optimization occurs at many scales, it seems, right down to the very fine grained, subtle noise characteristics. Quite impressive.
(FWIW, I am not one who likes to eliminate/obliterate noise...I like to have a bit of fine grained, low profile noise in my final images. So, the resulting noise after BXT and NXT is actually really important to me.) Jon Rista:
FWIW, I've always done BXT on multi-night data. In the end, the integration is a statistical result from all the various frames, each of which are scaled and redistributed to be optimally compatible with each other. BXT seems to work just fine on data that comes from a dozen or more different nights. BXT doesn't know about the individual frame statistics...it only knows about the final integration. Hi Jon. Yes I think that you are probably right about that. Up to this point I had assumed that Blur Xt was running some very smart version of Richardson-Lucy deconvolution but now I realise that that is just not the case and that the NN AI is really at the core of what it is doing. Normally deconvolution would not be commutative in that way --so I was scrupulous about keeping the imaging sessions separate doing the BlurXt sharpening first and then combining images. But in fact I suspect that the other way round will work better because BlurXt will then have better SNR data to work with - another experiment to do in itself :-). PS I think that it is fine-grained because at the scale shown you are close to seeing the individual pixels?
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
I don’t know the answer to your question. Interesting tests.
I will say that to my eye the left image (image with no BXT correction before stacking) looks a tad sharper. Not that they both won’t be equivalent with further processing.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Tim Hawkes:
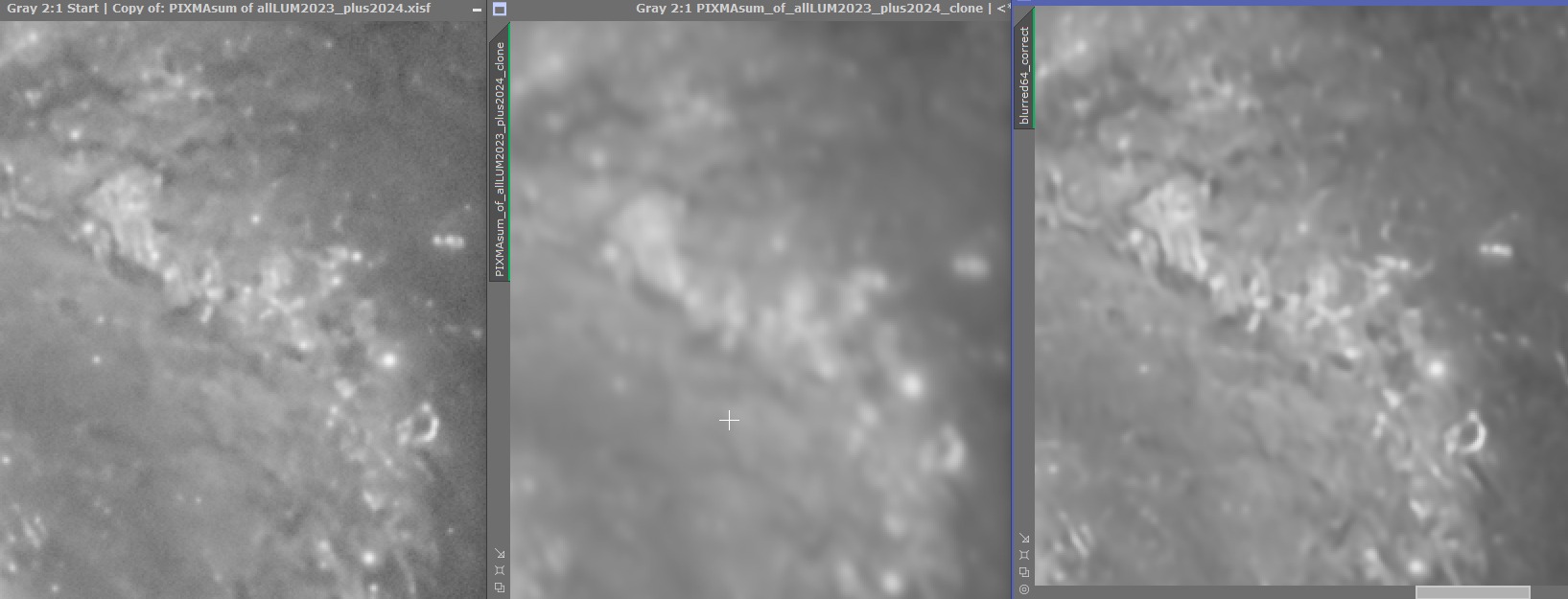
I suspect that the AI sharpening process needs input on the size of the PSF that it should minimize to as part of the target for iteration but has it's own internal model of all the various blurring effects that could alter the apparent shape of this PSF and so does not really need to take this information from actual measurements of the stellar PSFs in the image? This probably explains why it has does so well in deblurring images even where the star shapes aren't round? My test with the artificially oblong stars on artificial nebula features shows that it’s correction does correct nebula in the same direction also so I think this is why it is able to sharpen nebula in the correct direction when there is a symmetric blurring.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Steven Miller:
Tim Hawkes:
I suspect that the AI sharpening process needs input on the size of the PSF that it should minimize to as part of the target for iteration but has it's own internal model of all the various blurring effects that could alter the apparent shape of this PSF and so does not really need to take this information from actual measurements of the stellar PSFs in the image? This probably explains why it has does so well in deblurring images even where the star shapes aren't round?
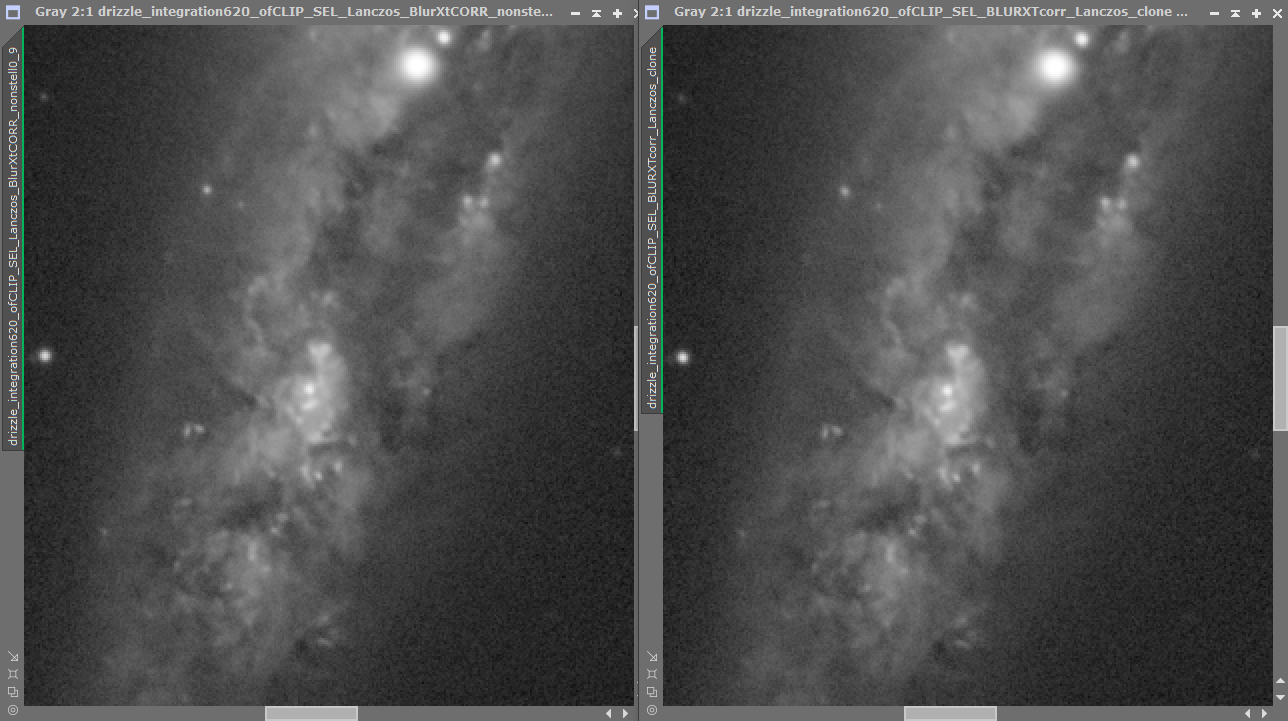
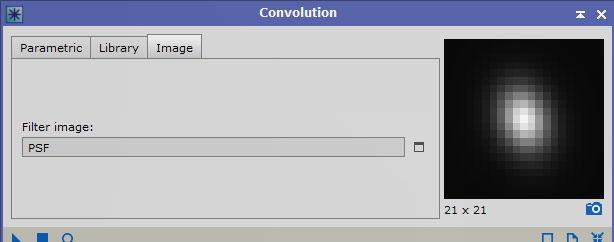
My test with the artificially oblong stars on artificial nebula features shows that it’s correction does correct nebula in the same direction also so I think this is why it is able to sharpen nebula in the correct direction when there is a symmetric blurring. Yes I saw that in your study - maybe the E =0.54 v 0.45 difference in my expt. wasn't big enough to see an effect? - so will probably try another comparison between more widely divergent data sets or perhaps also do it artificially and preconvolve with a few more highly distorted psfs and see how the non-stellar sharpening responds? So here is a detailed part of M51 from one of my images above ... then convolved with a fairly nasty PSF--Eccen ca 0.64 --- then subjected to BlurXt CORR and nonstellar sharpening again. BXT sort of recovers the starting image but seems to have oversmoothed it ? not sure what to make of it? 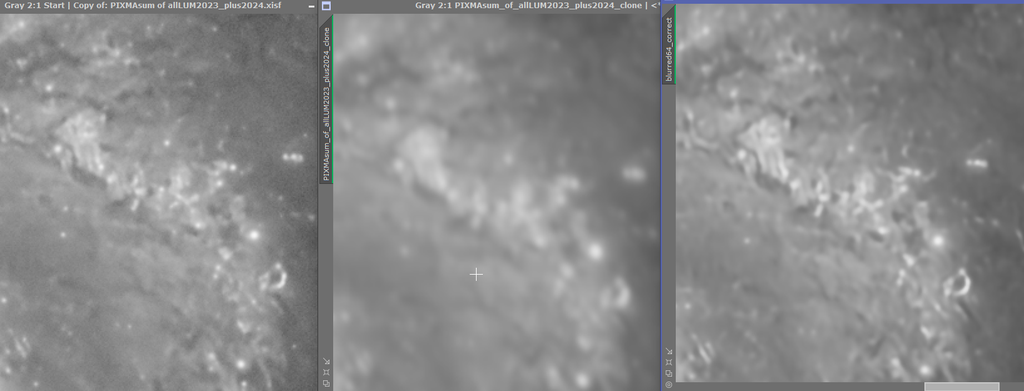 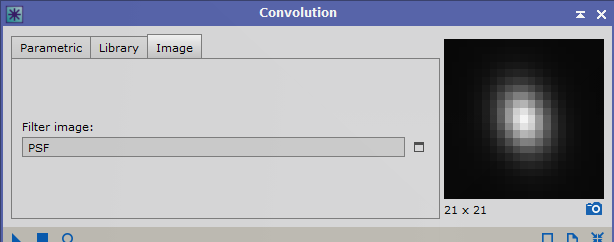 Certainly sharpness was lost and it ends up more blurred . Original image was F 3.44, E 0.48. After blurring it was F 7.5 and E 0.6 and then after BlurXt resharpening F 4.7 and E 0.55 (BXT star sharpening set at zero). Tim
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Well you are beyond my pay grade but I believe fundamental imaging science will tell you that when you convolve an image, deconvolution can’t fully recover the original image: Information is lost that can never be recovered.
So I would expect the deconvolved image to only be a partial reconstruction of the original. Exactly how much it loses and why is possibly very complex.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Tim Hawkes:
Steven Miller:
Tim Hawkes:
I suspect that the AI sharpening process needs input on the size of the PSF that it should minimize to as part of the target for iteration but has it's own internal model of all the various blurring effects that could alter the apparent shape of this PSF and so does not really need to take this information from actual measurements of the stellar PSFs in the image? This probably explains why it has does so well in deblurring images even where the star shapes aren't round?
My test with the artificially oblong stars on artificial nebula features shows that it’s correction does correct nebula in the same direction also so I think this is why it is able to sharpen nebula in the correct direction when there is a symmetric blurring.
Yes I saw that in your study - maybe the E =0.54 v 0.45 difference in my expt. wasn't big enough to see an effect? - so will probably try another comparison between more widely divergent data sets or perhaps also do it artificially and preconvolve with a few more highly distorted psfs and see how the non-stellar sharpening responds?
So here is a detailed part of M51 from one of my images above ... then convolved with a fairly nasty PSF--Eccen ca 0.64 --- then subjected to BlurXt CORR and nonstellar sharpening again. BXT sort of recovers the starting image but seems to have oversmoothed it ? not sure what to make of it?
Certainly sharpness was lost and it ends up more blurred . Original image was F 3.44, E 0.48. After blurring it was F 7.5 and E 0.6 and then after BlurXt resharpening F 4.7 and E 0.55 (BXT star sharpening set at zero).
Tim This is because BXT does not try to converge on a PSF of 0. Technically, if you were able to optimally converge on a PSF of 0, the original image should be perfectly restored. The problem is that perfection here is unattainable due to error (e), so BXT instead attempts to achieve near-perfection, where the error term is minimized, but not zeroed. So even though you convolved with a known PSF and used the same PSF to correct the extended signal, BXT would never be able to achieve perfect correction, as it simply isn't designed to do so.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Steven Miller:
Well you are beyond my pay grade but I believe fundamental imaging science will tell you that when you convolve an image, deconvolution can’t fully recover the original image: Information is lost that can never be recovered.
So I would expect the deconvolved image to only be a partial reconstruction of the original. Exactly how much it loses and why is possibly very complex. Yes I think that is right and sort of what you'd expect. I think it helps to demonstrate that whatever else Blur Exterminator is acting with 'integrity' -- i.e. the information is lost and thereafter it doesn't make stuff up by putting into place the same pieces of some almost pre-determined jigsaw but struggles and puts back a rather blurry picture in line with the increase in diameter of the psf that can be recovered after blurring. So I am really quite happy with that -- at least within the blurring range herein -- the quality of the picture out is dependent on the quality of the picture in. So I can trust what BlurXt is doing even if I don't understand it. The bit of the puzzle I am not yet clear about are the separate effects of PSF diameter size and Eccentricity since both were increased in this artificial blurring expt. Tim
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
Tim Hawkes:
Steven Miller:
Tim Hawkes:
I suspect that the AI sharpening process needs input on the size of the PSF that it should minimize to as part of the target for iteration but has it's own internal model of all the various blurring effects that could alter the apparent shape of this PSF and so does not really need to take this information from actual measurements of the stellar PSFs in the image? This probably explains why it has does so well in deblurring images even where the star shapes aren't round?
My test with the artificially oblong stars on artificial nebula features shows that it’s correction does correct nebula in the same direction also so I think this is why it is able to sharpen nebula in the correct direction when there is a symmetric blurring.
Yes I saw that in your study - maybe the E =0.54 v 0.45 difference in my expt. wasn't big enough to see an effect? - so will probably try another comparison between more widely divergent data sets or perhaps also do it artificially and preconvolve with a few more highly distorted psfs and see how the non-stellar sharpening responds?
So here is a detailed part of M51 from one of my images above ... then convolved with a fairly nasty PSF--Eccen ca 0.64 --- then subjected to BlurXt CORR and nonstellar sharpening again. BXT sort of recovers the starting image but seems to have oversmoothed it ? not sure what to make of it?
Certainly sharpness was lost and it ends up more blurred . Original image was F 3.44, E 0.48. After blurring it was F 7.5 and E 0.6 and then after BlurXt resharpening F 4.7 and E 0.55 (BXT star sharpening set at zero).
Tim
This is because BXT does not try to converge on a PSF of 0. Technically, if you were able to optimally converge on a PSF of 0, the original image should be perfectly restored. The problem is that perfection here is unattainable due to error (e), so BXT instead attempts to achieve near-perfection, where the error term is minimized, but not zeroed. So even though you convolved with a known PSF and used the same PSF to correct the extended signal, BXT would never be able to achieve perfect correction, as it simply isn't designed to do so. Yes that would indeed be a mechanism of information loss --and so things would look worse on every cycle. As in my answer to Steven I'm happy that that was the outcome - as expected when you think it through.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Tim Hawkes:
Jon Rista:
Tim Hawkes:
Certainly sharpness was lost and it ends up more blurred . Original image was F 3.44, E 0.48. After blurring it was F 7.5 and E 0.6 and then after BlurXt resharpening F 4.7 and E 0.55 (BXT star sharpening set at zero).
Tim
This is because BXT does not try to converge on a PSF of 0. Technically, if you were able to optimally converge on a PSF of 0, the original image should be perfectly restored. The problem is that perfection here is unattainable due to error (e), so BXT instead attempts to achieve near-perfection, where the error term is minimized, but not zeroed. So even though you convolved with a known PSF and used the same PSF to correct the extended signal, BXT would never be able to achieve perfect correction, as it simply isn't designed to do so.
Yes that would indeed be a mechanism of information loss --and so things would look worse on every cycle. As in my answer to Steven I'm happy that that was the outcome - as expected when you think it through. It might need to be noted, that as a neural network, whatever BXT is doing, is most likely very dissimilar to what we are generally familiar with regarding normal deconvolution algorithms. Something like Richardson-Lucy is distinctly iterative. Same logic, repetitively applied, iteration after iteration, in an attempt to converge on what the image was before it was convolved. Regularization and other things add layers of error-prevention, essentially an attempt to protect the algorithm from the noise (something not present in the "original" or "real" image) and other artifacts generated each iteration by the error produced by the algorithm. BXT, on the other hand, is a network of nodes, linked to each other in progressive series, with each node either making a decision, performing some transformation on the data, or both, and sending the result to the next node(s). This would not be an iterative process, I don't think (and Russ has made comment elsewhere that it shouldn't really be called deconvolution!) Instead, the NN would directly transform, little by little, the convolved image with the original PSF, into a better image convolved with a better PSF. So, I don't think that there are cycles with BXT. I don't think there are iterations. The image data passes through the neural network...starting out as f+g+n, and ending up as f+g'+n.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
I don't have time to read through all 4 pages…but has no one picked up that in the original post that one set of data was dithered and the other was not?
it is not an apples to apples comparison, and that the majority of the noise in the short exposure version is likely from the data not being dithered, and not necessarily from the exposure length?
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Tim Hawkes:
If the process of BXT sharpening is indeed to sequentially scan through mini-segments the input image and then replace the contents within each with the probable best candidate from a neural net library of "micro-features" (after accounting for the blurring) thent might that imply - beyond some threshold level of input quality- what you then stand to get out with any further increases in the input quality may become more and more marginal ? i.e. once a level of say 90-95% of correct neural replacements have been made then there might be diminishing returns? An input image only has to be good enough to trigger the correct replacements - and once nearly all correct there can be nothing much further to gain? I think that we tend to forget that any telescope larger than 4"-10" under the atmosphere is operating at a resolution below what it could do in a vacuum. There actually is a hard bandwidth limit for optical systems, which puts a limit on the ultimate image sharpness--even with the best deconvolution algorithm. Regardless, the algorithm that Russ has produced is almost certainly using a neural net to come up with "a best guess" of what the object looked like given blurring by a given PSF. If you run it over and over again, you'll see that the first guess is indeed almost always the best guess and that because you run into problems with making estimates from very small variations that mostly come from uncertainty in the data (AKA noise). So there are a couple of clear limitations. The first is the optical system itself and the second is noise within the data. The ultimate way to get even better results is to start with a larger scope under superb seeing conditions and to take a lot of high quality data! The good news is that Russ's algorithm can recover data take under pretty poor conditions to produce a pretty passable image. John
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
Thanks for the links! I totally understand Russ's desire to keep his super secret sauce super secret. It is his business after all. His tools are pretty amazing, and I respect his goal of protecting his critical IP.
The white paper is very enlightening. His approach is very interesting, and I think I understand now why the results can be so good...he isn't aiming for perfection, but instead aiming for a smaller PSF, g', to produce a better (but not perfect, i.e. zero-width PSF) image, h'. Kind of genius, actually.
I can also understand why he says this isn't necessarily deconvolution... Technically speaking, these days, neural networks generated from ML are so complex, we can no longer decipher or understand them. So it may well be that we simply cannot know exactly how the AI process takes f (or rather, f+g+n) and produces h'. HOWEVER it does it, the ultimate goal was actually to reduce the error, e... HOWEVER it happens, by minimizing e, Russ's product is able to arrive at a fairly optimal result (one in which the stars are NOT all single-pixel points of light, which would be incredibly boring (!!) but instead produces a natural result with a meaningful diversity of star sizes that make sense.)
Since the NN was designed to minimize the error, e, I am not so sure that there is any kind of data replacement going on. We can't know exactly what the NN is doing, it would be too complex to decipher. It may be that some of the training data had the stars replaced with more optimal exemplars, or that the source data itself was more optimal (Hubble or other carefully sourced and curated scientific data). Since the NN was produced with an algorithm who's purpose was to minimize the error between h' vs. f, then that's what the network will do. I don't think that requires replacing stars with other stars... The network should be able to directly produce the output image from the source image without any replacement. I had dinner with Russ a little over a week ago when he was in town to receive the very prestigious Progress Award from the Photographic Society of America. He is pretty close lipped about exactly what he had done in BXT and about what he is developing--and there is more to come. Our community is very fortunate that Russ decided to leave his job as a chip designer in order to devote his full time to developing tools for AP. He did tell me that his training data set is much smaller than the 300,000-500,000 samples that I guessed. He is also doing a lot more in BXT than I realized. Again, he did not tell me anything about his algorithm so I do not have any inside information. I did talk with him about an idea I had a few years about about fitting clipped stellar profiles to "restore" the full profile and he responded that BXT already does that. The one thing that Russ emphasizes is that his algorithms do NOT incorporate any kind of generative AI. His algorithms basically solve the problem using linear algebra--there are just millions of equations being solved simultaneously and no one knows what they are! That's the genius of neural net solutions. You give it training data and a figure of merit and let it figure out the right coefficients to produce the best "guess" at a solution. Russ seemed to indicate that he does not use Hubble data but I didn't get an opportunity to dig into that comment (I wasn't with him one on one.) I agree that BXT is not performing any sort of mathematical deconvolution; however, the net result is exactly the same and the term "deconvolution" has always referred to anything that undoes the convolution process that blurs images. And, that is exactly what Russ's algorithm is doing. So, I'm comfortable calling it a deconvolution process. John
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.