Alan Brunelle:
Kyle Goodwin:
Alan Brunelle:
Kyle Goodwin:
Your assumptions about licensing for GPU usage are incorrect. The GPU compute architecture for NVidia (CUDA) as well as similar systems for AMD as well as the standardized one like OpenCL and DirectCompute are freely usable by any developer. There is no need for “inclusion in a driver” either. Games show up there because they add optimizations for certain games sometimes, but not because you have to pay NVidia to be able to use the GPU.
Maybe I am incorrect. But my words reflect those of what I read on the PI forums by "well-known" people there  . I certainly could believe that Nvidia might provide free support to game companies to add value to their hardware. On the other hand, the pressure for game companies to pay for such attention is not only logical or life-sustaining, but seems to be the way the world works. So if you absolutely know that you are correct, i.e. work in the management of these companies that do the negotiations, then fine, but at this point, I would not bet on that. I know that you did not mean that I said that drivers are needed or asked for. If my memory serves me, my Nvidia updates typically state that "Now includes support for... or Now with updated support for... and then followed by a very long list in small print of the companies and games newly supported. . I certainly could believe that Nvidia might provide free support to game companies to add value to their hardware. On the other hand, the pressure for game companies to pay for such attention is not only logical or life-sustaining, but seems to be the way the world works. So if you absolutely know that you are correct, i.e. work in the management of these companies that do the negotiations, then fine, but at this point, I would not bet on that. I know that you did not mean that I said that drivers are needed or asked for. If my memory serves me, my Nvidia updates typically state that "Now includes support for... or Now with updated support for... and then followed by a very long list in small print of the companies and games newly supported.
I run a video streaming company. We’re a vendor to all the major cable and telephone companies. We use GPUs in our products for video processing. I’m certain I understand the license requirements surrounding developing applications with them.
So it is your company's video processing software that you use to process your videos? That should be the video software responsibility and the cost built into the cost of the software you use. Just wanting to be sure of the facts, not that it is all that critical of the conversation here.
After doing a quick search on line it is very clear that Nvidia certainly limits its licenses for certain tasks. It can be especially restrictive for commercial applications. Seems much less so for research and development purposes. In having to sign up for the developer's newsletters to download the CUDA, etc. for using BXT, its clear that Nvidia is seeking to have as many developers wanting to work on their systems as possible, so that is free, indeed. The question still remains about whether Nvidia is paid a license fee by commercial developers, especially ones that get the special attention where Nvidia posts that their upgraded firmware now supports a particular game... The fact that Nvidia advertises a "free" Inception program for Startup companies suggest that otherwise fees are involved beyond startup. That they also appear to offer a number of different partner level programs suggest otherwise as well, unless these partnerships are all one-way.
Maybe to your point, I too have some doubt as to GPU licensing being a hurdle for PI adopting GPU acceleration more generally. For PI, maybe the bigger issue is really dealing with the technical issues specific and different for each graphics card manufacturer. Yes, we produce the software which processes the video. We do not pay NVidia a licensing fee. We do purchase their GPUs and belong to their developer program (for free). I’m not going to spend any more time debating the licensing structure around developing software to run on GPUs. It isn’t an impediment to Pixinsight developing support for it. The impediment is development time and costs, which is plenary hurdle enough for a small company with many other priorities. I think this discussion has hijacked the thread for long enough, so I will bow out.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Timothy Martin:
Alan Brunelle:
For me, doing a BXT run on my old 2060 gets the job done in under a minute.
Given that I have two scopes using IMX455 sensors--both drizzled to 2X--and two scopes using the IMX461, it takes me a bit longer than that even with the 3090. The real time suck is SXT. And on more complex images, I may need to run that five times (once each for L, the combined RGB, a clone of R used for continuum subtraction, Ha, and a clone of RGB to actually produce the stars). It takes around 2 to 3 minutes each. So let's say I cut that time to one minute average (maybe that's ambitious), that's conservatively 5 minutes saved processing a single image. I typically process each image around five times as I gather data on a target. So that's now a savings of 25 minutes saved. With four scopes cranking every clear night, I should produce about 200 images per year, that's 80+ hours saved per year. That's not accounting for any time saved on BXT and NXT. It would also smooth out the workflow a bit and make it that much more enjoyable.
I use APP exclusively to stack. So while one image is stacking, I can at least work on another one in PI. If I were to stick with 768GB of RAM, I'm intrigued by the idea of stacking on a RAM disk. Time for stacking is indeed a big concern, but it's secondary to speeding up things in PI. I do see your intent on maximizing your throughput! Your desires are pretty demanding. And that is a personal thing. Given my age, and the fact that I am just clearing a cancer threat from 2.5 years ago, I also understand how time is a critical thing for you. I am not there yet as far as time spent on astroimaging. However, I do want to do some things before I go. I also understand that no matter what I do, on the last day, I will still have a list that is uncompleted! So, under my more relaxed approach, none of the xXT functions is really a limiting thing for me. Those all run well enough for me[i], [/i]using my RTX2070. A bit of time, yes especially for STX. However, I think you will face a practical issue in trying to pay your way through the time issue. First of all, you will never recover all 80 hours no matter what you do if using any PC. More importantly, if you could try before you buy, to clearly establish that the hardware and software will do what you think or want it to do could save you a lot of wasted money. For acceleration with the xXT suite, you typically see an acceleration of ~9x vs, non-GPU performance. Of course, everyone is comparing their GPU vs. CPU performance on their own machine. So for those who have hot new machines, I would like to see what their times for work are in today's world. Bottom line is, if you spend $12,000 more on a computer and get a 50% reduction in processing time compared to an older GPU, would you be happy with that? Thats seem achievable. But better than that? I don't know. And until you've bought and paid for a new rig, neither do you. Unless you can try before you buy or get someone here to offer their experience with a system close to what you want. If you could run SXT as a separate instance, and do that 5X you could save a ton of time, no matter what by doing all your star removal at once. Not sure the GPU would stand for that. For me, the biggest time hog in post processing ends up being Multiscale medium transform. I rarely use it anymore, but need to if I have large scale noise to deal with. NXT does a fine job an small scale noise, and fast, as I am sure you know. MMT can deal with large scale noise, but to get that large scale noise fixed, I need to work with added layers. And it is extremely slow. I typically set it up and then go make dinner, etc. Hence my desire to see PI adopt GPU acceleration broadly. Best of luck and keep us posted as to your choices and experiences. Alan
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Timothy Martin:
Kyle Goodwin:
not feeling slow enough that I'd want to drop $15k+ on a computer that will depreciate to 0 in 5 years.
Five years is a long time to me. I'll be 70 in five years. Money, I've got. Time is another matter. Saving a few minutes here and there may not seem like much, but it adds up. As I get closer to the septuagenarian mark, I want to spend as little time as possible watching an hourglass turn on a computer screen. Time efficiency is something I'm obsessed with. I think at any age, one should take that seriously. I'd say go for it if you can. But there soon will be a release of the 5090x series. Maybe you'd want to wait for a couple of months.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Timothy Martin:
The real time suck is SXT. And on more complex images, I may need to run that five times (once each for L, the combined RGB, a clone of R used for continuum subtraction, Ha, and a clone of RGB to actually produce the stars). It takes around 2 to 3 minutes each. Just some input regarding SXT. Why don't you simply run it once on the combined linear RGB data and extract the channels afterwards? Seems a bit unnecessarily complex to do so many runs. Then you're down to three in stead of five.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Timothy Martin:
Alan Brunelle:
For me, doing a BXT run on my old 2060 gets the job done in under a minute.
Given that I have two scopes using IMX455 sensors--both drizzled to 2X--and two scopes using the IMX461, it takes me a bit longer than that even with the 3090. The real time suck is SXT. And on more complex images, I may need to run that five times (once each for L, the combined RGB, a clone of R used for continuum subtraction, Ha, and a clone of RGB to actually produce the stars). It takes around 2 to 3 minutes each. So let's say I cut that time to one minute average (maybe that's ambitious), that's conservatively 5 minutes saved processing a single image. I typically process each image around five times as I gather data on a target. So that's now a savings of 25 minutes saved. With four scopes cranking every clear night, I should produce about 200 images per year, that's 80+ hours saved per year. That's not accounting for any time saved on BXT and NXT. It would also smooth out the workflow a bit and make it that much more enjoyable.
I use APP exclusively to stack. So while one image is stacking, I can at least work on another one in PI. If I were to stick with 768GB of RAM, I'm intrigued by the idea of stacking on a RAM disk. Time for stacking is indeed a big concern, but it's secondary to speeding up things in PI. I think the PCIe nVME drives have surpassed RAM drives in terms of performance now. Last time I checked, a ram drive delivered around 7GB/s read performance, and a little less write performance. A PCIe 4 nVME will get you AT LEAST that, if not more. A PCIe 5 nVME can get you at least 12.4GB/s now, and theoretically still a bit more than that (I don't know if anything faster than 12.4 has been released yet.) I would think using the fastest nVME drive you can get your hands on would be sufficient to maximize throughput from drive to ram. I do think that a well programmed 4090 would help speed up the compute-heavy processing in PI. I don't know how much PI or its processes can use a GPU. If SXT, BXT, etc. already work on a GPU, then a 4090 is very, very powerful.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
Timothy Martin:
Alan Brunelle:
For me, doing a BXT run on my old 2060 gets the job done in under a minute.
Given that I have two scopes using IMX455 sensors--both drizzled to 2X--and two scopes using the IMX461, it takes me a bit longer than that even with the 3090. The real time suck is SXT. And on more complex images, I may need to run that five times (once each for L, the combined RGB, a clone of R used for continuum subtraction, Ha, and a clone of RGB to actually produce the stars). It takes around 2 to 3 minutes each. So let's say I cut that time to one minute average (maybe that's ambitious), that's conservatively 5 minutes saved processing a single image. I typically process each image around five times as I gather data on a target. So that's now a savings of 25 minutes saved. With four scopes cranking every clear night, I should produce about 200 images per year, that's 80+ hours saved per year. That's not accounting for any time saved on BXT and NXT. It would also smooth out the workflow a bit and make it that much more enjoyable.
I use APP exclusively to stack. So while one image is stacking, I can at least work on another one in PI. If I were to stick with 768GB of RAM, I'm intrigued by the idea of stacking on a RAM disk. Time for stacking is indeed a big concern, but it's secondary to speeding up things in PI.
I think the PCIe nVME drives have surpassed RAM drives in terms of performance now. Last time I checked, a ram drive delivered around 7GB/s read performance, and a little less write performance. A PCIe 4 nVME will get you AT LEAST that, if not more. A PCIe 5 nVME can get you at least 12.4GB/s now, and theoretically still a bit more than that (I don't know if anything faster than 12.4 has been released yet.) I would think using the fastest nVME drive you can get your hands on would be sufficient to maximize throughput from drive to ram.
I do think that a well programmed 4090 would help speed up the compute-heavy processing in PI. I don't know how much PI or its processes can use a GPU. If SXT, BXT, etc. already work on a GPU, then a 4090 is very, very powerful. *Yes I had forgotten to mention your reference to the PCIe NVME option. And pretty easy and cheap to install. One thing that might be good to consider in the build is to ensure that this reside on the primary bus. Not sure how big a factor, but my build instruction made me aware of the logic of those choices. Thereby considering priority in the communications to CPU and drive, but also shared bandwidth through the bus. Because of this, the raw numbers for NVME might not be the whole story in practice but just potential. Tim's builder should be aware of that, assuming goals for the build are communicated. For my build, I put my boot drive (also where my swap folders resided) on the main bus and honestly the RAMdisk outperformed it but a bit. My drive was not one of the high speed ones. Random instability drove me to return my swap folders to my NVME. Maybe I didn't have enough RAM for that. In any case busses are shared and that should be understood. Performance may depend on other operations, etc concurrently underway. In any case, setting up a RAMdisk or two or three is easy and can be tested simply. Just as easily, they can be removed easily since it's just a software setup. But all this may be irrelevant for SXT if the GPU doesn't use that. I appreciate that newer GPU cards are very much more powerful, with new ones having dramatic increases in specs. I think my question is how does that translate to the specific applications discussed? My 2070 takes <20 sec to do an NXT on my 1.2 GB files. And probably ~3 min for SXT. Recall that Tim said money was no object. The most powerful RTX card is 20-40 times what my 2070 cost me back then. And at the time the 2070 was no overachiever. What does 20x get you? Please someone tell me that they get an NXT to complete in one second and SXT in 15 seconds. Anyone can easily monitor if and to what extent the workload falls on the CPU vs GPU in the monitor window. Never seen the GPU budge from idle position during any PI function that does not specifically call on the GPU such as SXT. Even when my CPU cooler fan is cranking at full speed. When running SXT, the GPU then pegs, and the CPU activity craters and the CPU fan slows to lowest rate. I think a graphics card will do little to accelerate any regular PI function. Probably would work just fine with only on board graphics. But clearly these normal functions do heavily rely on the multiple core structure of these CPUs.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Alan Brunelle:
Jon Rista:
Timothy Martin:
Alan Brunelle:
For me, doing a BXT run on my old 2060 gets the job done in under a minute.
Given that I have two scopes using IMX455 sensors--both drizzled to 2X--and two scopes using the IMX461, it takes me a bit longer than that even with the 3090. The real time suck is SXT. And on more complex images, I may need to run that five times (once each for L, the combined RGB, a clone of R used for continuum subtraction, Ha, and a clone of RGB to actually produce the stars). It takes around 2 to 3 minutes each. So let's say I cut that time to one minute average (maybe that's ambitious), that's conservatively 5 minutes saved processing a single image. I typically process each image around five times as I gather data on a target. So that's now a savings of 25 minutes saved. With four scopes cranking every clear night, I should produce about 200 images per year, that's 80+ hours saved per year. That's not accounting for any time saved on BXT and NXT. It would also smooth out the workflow a bit and make it that much more enjoyable.
I use APP exclusively to stack. So while one image is stacking, I can at least work on another one in PI. If I were to stick with 768GB of RAM, I'm intrigued by the idea of stacking on a RAM disk. Time for stacking is indeed a big concern, but it's secondary to speeding up things in PI.
I think the PCIe nVME drives have surpassed RAM drives in terms of performance now. Last time I checked, a ram drive delivered around 7GB/s read performance, and a little less write performance. A PCIe 4 nVME will get you AT LEAST that, if not more. A PCIe 5 nVME can get you at least 12.4GB/s now, and theoretically still a bit more than that (I don't know if anything faster than 12.4 has been released yet.) I would think using the fastest nVME drive you can get your hands on would be sufficient to maximize throughput from drive to ram.
I do think that a well programmed 4090 would help speed up the compute-heavy processing in PI. I don't know how much PI or its processes can use a GPU. If SXT, BXT, etc. already work on a GPU, then a 4090 is very, very powerful.
*Yes I had forgotten to mention your reference to the PCIe NVME option. And pretty easy and cheap to install. One thing that might be good to consider in the build is to ensure that this reside on the primary bus. Not sure how big a factor, but my build instruction made me aware of the logic of those choices. Thereby considering priority in the communications to CPU and drive, but also shared bandwidth through the bus. Because of this, the raw numbers for NVME might not be the whole story in practice but just potential. Tim's builder should be aware of that, assuming goals for the build are communicated. For my build, I put my boot drive (also where my swap folders resided) on the main bus and honestly the RAMdisk outperformed it but a bit. My drive was not one of the high speed ones. Random instability drove me to return my swap folders to my NVME. Maybe I didn't have enough RAM for that. In any case busses are shared and that should be understood. Performance may depend on other operations, etc concurrently underway. In any case, setting up a RAMdisk or two or three is easy and can be tested simply. Just as easily, they can be removed easily since it's just a software setup. But all this may be irrelevant for SXT if the GPU doesn't use that.
I appreciate that newer GPU cards are very much more powerful, with new ones having dramatic increases in specs. I think my question is how does that translate to the specific applications discussed? My 2070 takes <20 sec to do an NXT on my 1.2 GB files. And probably ~3 min for SXT. Recall that Tim said money was no object. The most powerful RTX card is 20-40 times what my 2070 cost me back then. And at the time the 2070 was no overachiever. What does 20x get you? Please someone tell me that they get an NXT to complete in one second and SXT in 15 seconds.
Anyone can easily monitor if and to what extent the workload falls on the CPU vs GPU in the monitor window. Never seen the GPU budge from idle position during any PI function that does not specifically call on the GPU such as SXT. Even when my CPU cooler fan is cranking at full speed. When running SXT, the GPU then pegs, and the CPU activity craters and the CPU fan slows to lowest rate. I think a graphics card will do little to accelerate any regular PI function. Probably would work just fine with only on board graphics. But clearly these normal functions do heavily rely on the multiple core structure of these CPUs. If you really want to maximize data throughput with both nVME drives as well as high performance GPUs, you will really want to get a motherboard and CPU that delivers a significant number of PCIe lanes. The average consumer chipset these days, sadly, do NOT offer enough lanes to allow you to get both full performance out of the GPU AND full performance out of a PCIe 5 nvME drive at the same time. It seems lane count has become another upsell factor, and most consumer grade motherboards offer 20+8 PCIe lanes. That's 20 for the various slots, both video cards and other peripherals, as well as nVME drives. If you get a 16x lane GPU card, you have only 4x lanes left for a single nVME drive. Its a rather annoying state of affairs (I built a new computer last year and ran into this...compared to my old motherboard, an ASUS Rampage VI Black Edition which had IIRC 40 PCIe 3.0 lanes, as well as a number of PCIe 2.0 lanes...significantly more than modern PCIe 4/5 motherboards.) To really get the full performance, you will want to look into higher grade chipsets and motherboards, maybe even higher end cpus (i.e. Xeon). I did not build such a system last year, as I needed to get a computer going fast and I ended up picking up some consumer grade parts just to get myself back to working order, but I did research a number of the higher end enthusiast and lower end server boards that use Xeon cpus, with lane counts from around 80 up to 128 (or maybe it was 152) PCIe 4 and/or 5. With such a motherboard and cpu, you could run a heck of a lot of drives, or a heck of a lot of video cards, or if you find just the right board, a decent mix of both. Beware of which slots you use on a consumer grade motherboard as well. A lot of these motherboards have a switch that will either disable or reduce the lane count of the primary 16x peripheral slot if you plug something into the "other end" of those lanes. Often the same 16 lanes will be shared with say an 8x slot and either one or two M.2 slots for nVME 4x drives, and if you use any of those other slots, the 16x lane will get disabled. Or you may have two M.2 slots, which will reduce the 16x peripheral slot to an 8x. Sadly, its become a very complicated endeavor to find a motherboard capable of delivering what you need if you need to be able to do both I/O heavy and GPU heavy operations concurrently. You need to make SURE that there is at least one M.2 4x slot for the drive that does NOT switch the primary 16x video card slot to 8x. Usually this is possible, but you need to make sure you know which slots to use to ensure that this is indeed the case. (Back when I was scouting out motherboards for my new build, I don't think I was able to find one that could use both the PCIe 5.0 M.2 4x slot at the same time as a GPU. I ended up using a PCIe 4.0 M.2 4x slot, which works at full speed and concurrently with the GPU at full 16x. Not that it mattered much...there really weren't any PCIe 5 nVME drives available. Even now, they seem to be pretty scarce and the high performance ones are still rather expensive.) This is actually a conundrum for the next generation of Radeon and nVidia GPUs. I hear they are going to be PCIe 5.0, requiring at least a full 16x (and something like a 5090, at the performance levels such a card might deliver, may not necessarily be possible with just 16 lanes!), which will further hamper the ability to use PCIe 5 nVME drives (unless, that is, you are using something like one of the modern Xeon boards that have 80+ lanes and plenty of full speed slots for everything!)
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Like Jon said, PCI lanes on consumer hardware are abysmal. My hopes are the mad dash to do LLM development bring some of the higher PCI lanes to commodity PCs because if they don't, Apple's unified memory architecture will beat them to the ground.
For me, that meant threadrippers but if you don't want to overspend, you can get prior generations of EPYCs and some mid range motherboards with TONS of PCI lanes for memory and video cards.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Byron Miller:
Like Jon said, PCI lanes on consumer hardware are abysmal. My hopes are the mad dash to do LLM development bring some of the higher PCI lanes to commodity PCs because if they don't, Apple's unified memory architecture will beat them to the ground.
For me, that meant threadrippers but if you don't want to overspend, you can get prior generations of EPYCs and some mid range motherboards with TONS of PCI lanes for memory and video cards. That's right, its the Threadrippers which have up to 120+8 lanes. The new Xeon cpus have 80+8 lanes (and 88+8 for the 6900 series, but who knows when that will actually materialize), but are pretty freakin beastly (IIRC, TDP is 500W!!!) In either case...PRI-CY!! I really hope you are correct about LLM/AI and such, and heck even next-gen gaming with next-gen video cards...and that they will bring greater lane counts to consumer-grade products. I think the issue occurred here when the lane management shifted from the chipset to the CPU. When chipsets were managing the links, which was last done with PCIe 3.0, a lot of pins on the chipset could be dedicated to lanes. With CPUs managing the links now, pin count starts to become a real estate issue... The latest Threadripper and Xeon cpus are freakin HUGE area wise. I suspect that's part of the problem. Would be nice to get back to the chipsets being able to handle it, but, its a bottleneck, and the raw throughput could probably never be realized that way now.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Astro Pixel Processor is clearly the way to go if you want to leverage GPU for stacking. But honestly I would reach out to that developer in their forums to ask what would have the largest impact on performance (whether it's two GPUs, or more CPU performance). It's possible the software can't access more than one GPU. There are also significant performance gains under Apple's M architecture for processing on APP as well vs. Intel. I don't know how that's changed over time, but when it was introduced it was about 30% faster than Intel. PixInsight development team is not prioritizing GPU acceleration at all. The next major release is supposed to add native M support for Apple with a 1.9 release. But again, fastest machines today on PixInsight are CPU bound, and fastest on Linux and not Windows. Just look at the benchmark charts for PixInsight that they maintain. https://pixinsight.com/benchmark/ |
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Andrew Burwell:
PixInsight development team is not prioritizing GPU acceleration at all. The next major release is supposed to add native M support for Apple with a 1.9 release. But again, fastest machines today on PixInsight are CPU bound, and fastest on Linux and not Windows. Just look at the benchmark charts for PixInsight that they maintain. https://pixinsight.com/benchmark/ Correction, looks like Windows is above Linux these days. Apple is only slightly behind overall, but that's running Intel emulation. So I suspect it will be in line with the top Intel/AMD processors after 1.9.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Andrew Burwell:
Andrew Burwell:
PixInsight development team is not prioritizing GPU acceleration at all. The next major release is supposed to add native M support for Apple with a 1.9 release. But again, fastest machines today on PixInsight are CPU bound, and fastest on Linux and not Windows. Just look at the benchmark charts for PixInsight that they maintain. https://pixinsight.com/benchmark/
Correction, looks like Windows is above Linux these days. Apple is only slightly behind overall, but that's running Intel emulation. So I suspect it will be in line with the top Intel/AMD processors after 1.9. I was going to mention that Windows is doing pretty darn well these days. I don't know if it was just how windows handled platter disc drives, or what, but since people have largely shifted to nVME solid state drives, but also with some of the latest Ryzen and Intel cpus, Windows is at the very least holding its own. The Apple M2 cpus should perform very well, if the application is properly optimized for them. Its good to know some apps are optimizing to take advantage of the additional capabilities of the Apple cpus. For any pixel processing work (which is basically all of what we do with astro processing, both pre- and post-), GPUs should theoretically provide the greatest advantages. Ideally, being able to farm work out to multiple GPUs should net the biggest gains. I don't know why PixInsight hasn't gotten on that bandwagon yet. One of the biggest hurdles for multiple gpu processing is the lane counts. If you don't have enough PCIe lanes to have full 16x performance on every GPU card, then you won't get the full benefit, and most consumer grade motherboards and cpus today only support 20 lanes in total, which means just one GPU. The shift of PCIE lanes to being managed by the CPU rather than the chipset really hampered progress there (or perhaps, did exactly what was intended, force anyone who wants more lanes into the Threadripper and Xeon arenas...)
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
I recently built a new computer after my old one died. I chose an RTX 4070 12GB and it handles PixInsight just fine. The main CPU is Ryzen 9 7900X with 64GB DDR5. Running StarXterminator even on large resolution image with dense stars usually doesn't take longer than 3 minutes. Two 4090s would be way overkill!
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
I use a Ryzen 5950x and a Radeon 7900xtx. I was able to build the tensorflow.so for the radeon 7900xtx using ROCM 6 so GPU acceleration for plugins that can use it work great while processing full frame images.
My next build will be a threadripper or EPYC for sure and i'm waiting see what AMD does to compete with unified memory on apple.
I do wish PixInsight or Siril could even justt use the GDDR ram even if they don't want to run calculations on GPU. I've got 24gb of GDDR6 memory that would be a whole heck of a lot faster than "swapping to disk" on large integrations.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
So after all the posts above, can someone recommend a configuration with a company to build a windows laptop computer with say 128 mb ram , threadripper or ryzen computer with nvidia Gpu and two 2tb SSD's with the appropriate configuration.
I am a mac user and would like a windows computer for my upcoming observatory build.
Thanks all.
Vic
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Victor:
So after all the posts above, can someone recommend a configuration with a company to build a windows laptop computer with say 128 mb ram , threadripper or ryzen computer with nvidia Gpu and two 2tb SSD's with the appropriate configuration.
I am a mac user and would like a windows computer for my upcoming observatory build.
Thanks all.
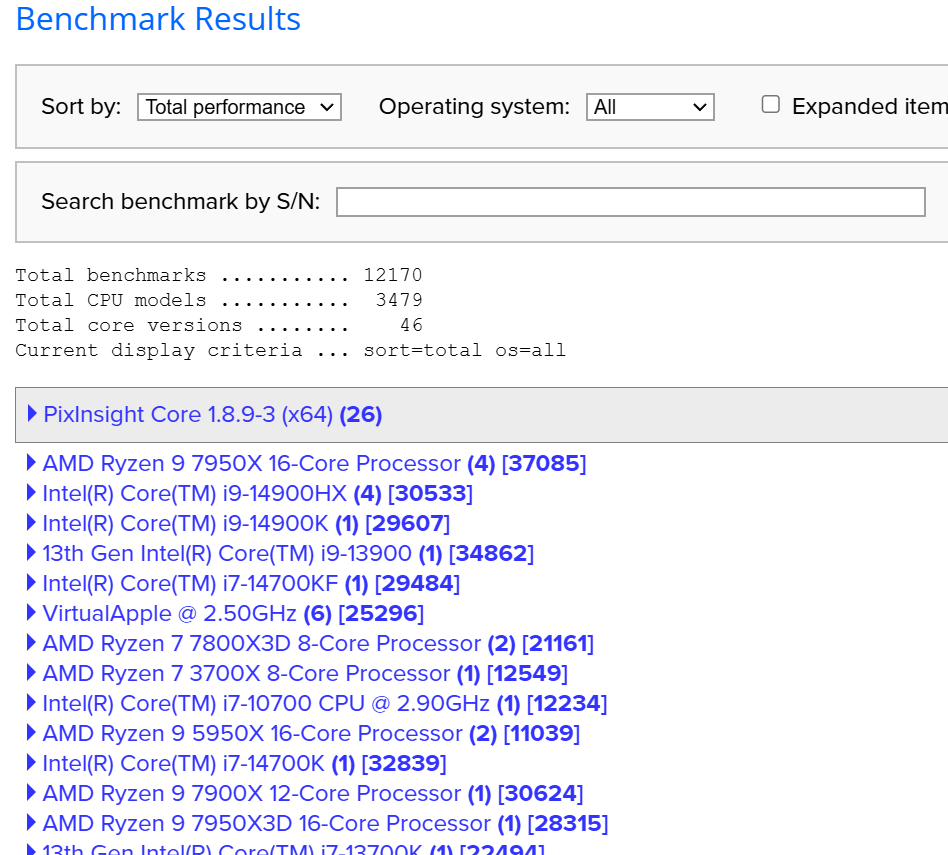
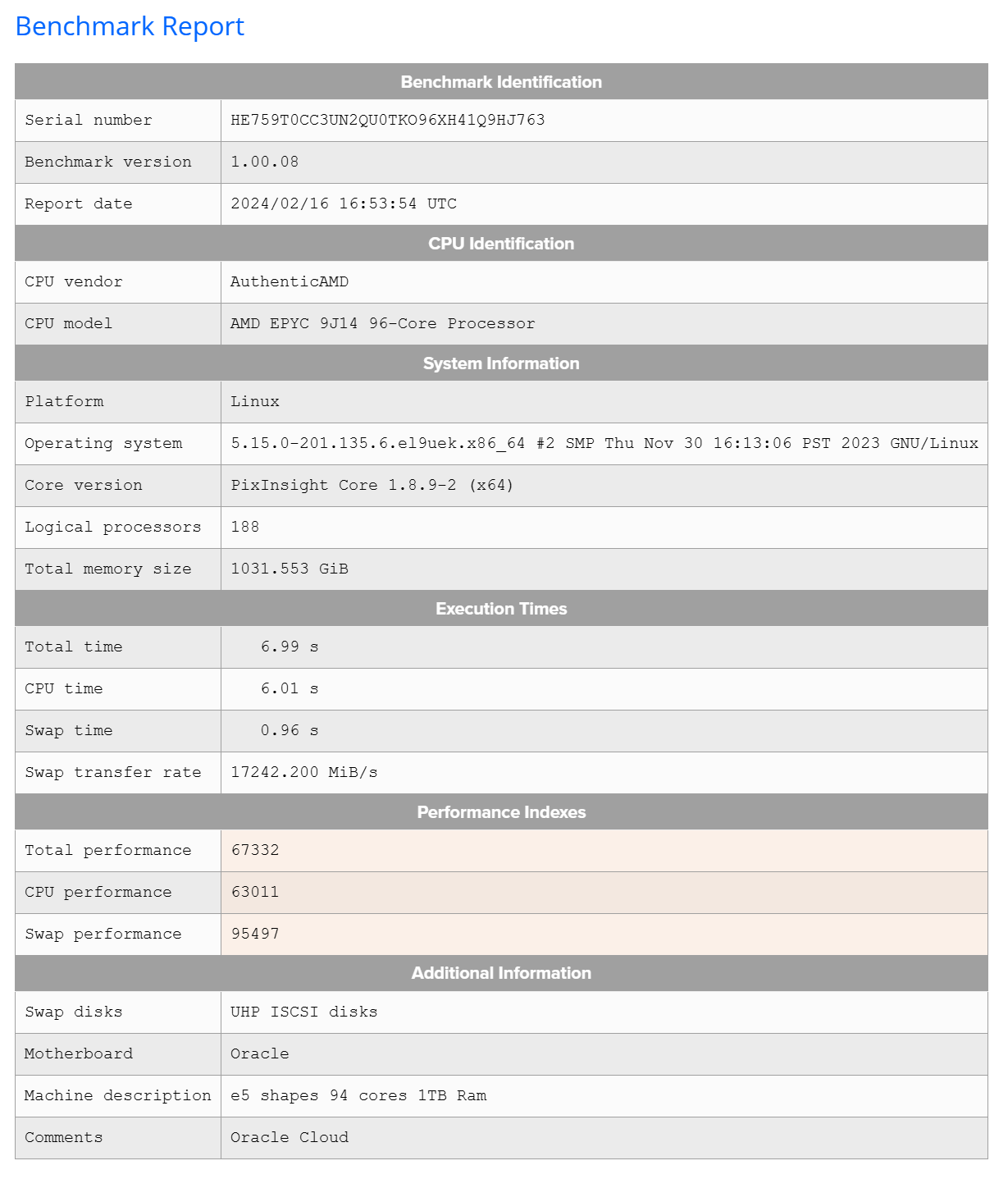
Vic Well, if you are into using PixInsight, one thing to do is go to their benchmark page ( https://pixinsight.com/benchmark/) and look up the performance you want. See clip here: 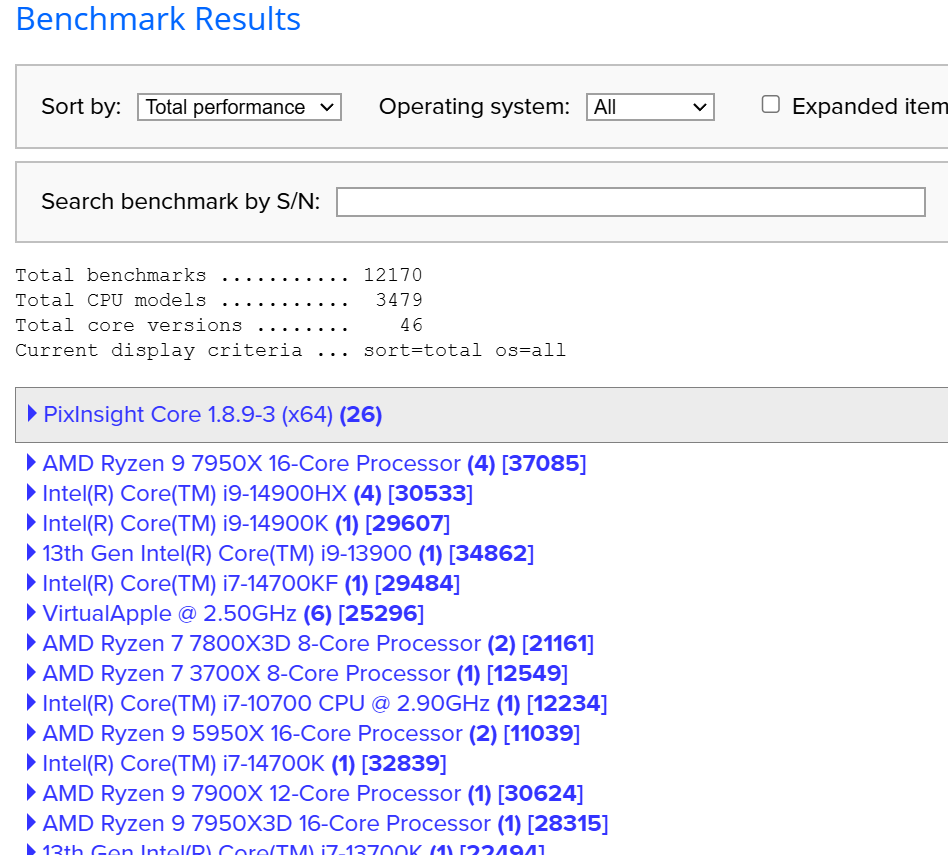 Click on the machine title and you can see more info at a high level of what the score was and the machine description:  Then click on the hyperlinked serial number and it will give you more details of the build: 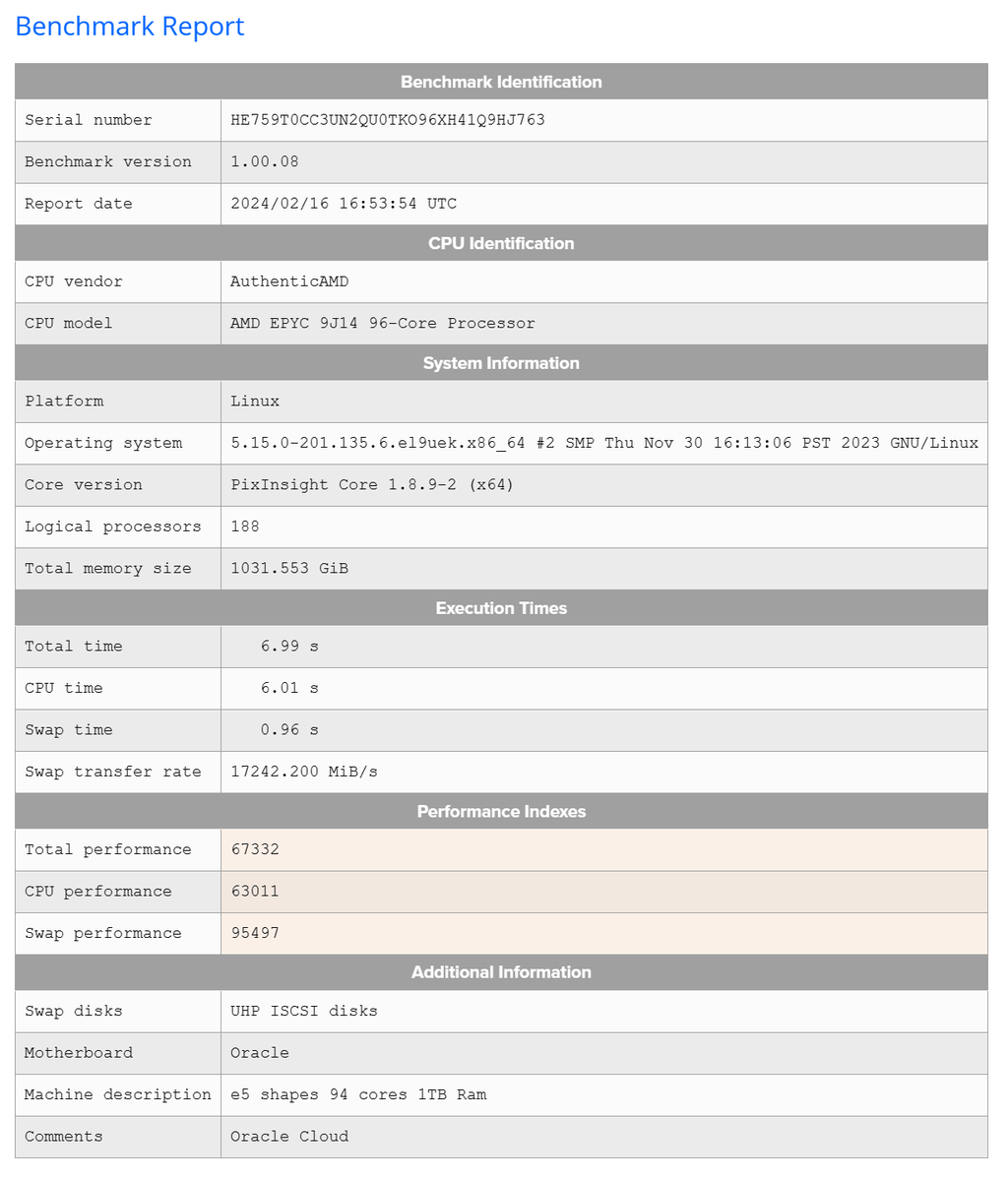 So, pick the performance you want from the scores (and times to completion) get the info on the computer that gave you that performance, then price out the components. Take some sedatives prior to the pricing, because to get that top performance you will be laying out a lot of money. But if you price out components, then you can try to get into your budget range. (Note: the above example has a comment "Oracle Cloud". I assume this individual is not the owner of the stated computer but is buying time on the computer via cloud computing.) Epyc processors, just the processor alone, cost multiple times what my whole machine cost. If you use other processing software and methods, not sure how this data would translate. In any case, pick the performance you want, with the operating system you use, get the data sheet like above, print it out and walk into a computer builder. Point to the sheet and tell them to "make that"... For "that" you save ~20 seconds of processing time (bench test comparison of above example to many common, and sufficiently powered users computers here.) if you use the example above and it will only cost you a small fortune. If this is what certain people need, then I hope they are collecting only the very best data from the very best optics for multiple targets every night to need that kind of processing, which really is only marginally relevant to any of the software that is used for astrophotography. For PI, the cpu count/ threads makes a real difference. But these are really incremental, do not seem to scale linearly, yet the cost seem to scale logarithmically. The PixIsight benchmark page is really interesting and the benchmarks have some utility during setup of a system. What is sad is to see is for some of these super PC's benchmarked with killer CPU performance numbers yet the total performance numbers being essentially no better than my 5 YO build at $1200 because the user doesn't know how to set up the swap disks. I sure hope what is displayed on the benchmark page is just their test results as they incrementally sorted out their swap disk setup to max performance. Regarding GPU, I keep seeing numbers of performance, for times to completion for a SXT run, of about 3 minutes for those who report that info here. What is remarkable is that my RTX2070 with 4GB of RAM gets the job done in under 3 minutes on an image that is 12,504 X 8352 pixels. That is compared to newer and more highly rated GPUs. So yes, GPU acceleration for just these few tasks makes a difference, but I have yet to see numbers that relate to any significant boost in the performance characteristics, TFLOPs, GPU RAM, etc. of the GPU to SXT time to completion. To me, this indicates that the type of activity that the makers of these AI-based tasks are not using the higher level capabilities of the GPU at all. Certainly it seems that multiple GPUs would be a waste of time, currently. I remember when I first started to use the AI-based functions available to PI users or as stand alone, the builders of these softwares stated in their documentation that the best thing to do was to get the rather lower end, less expensive GPU to employ their software. Clearly that advice still seems relevant today.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Unless you’re ok doing preprocessing/calibration in Astro Pixel Processor which does use the GPU. Processing the same stack in Pix vs APP can go from 30 minutes to 6 minutes. It’s at least worth downloading the free trial so you can do your own benchmarks and compare on your current computer systems the difference in speed.
I would still do all my post processing in PixInsight.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Alan Brunelle:
Victor:
So after all the posts above, can someone recommend a configuration with a company to build a windows laptop computer with say 128 mb ram , threadripper or ryzen computer with nvidia Gpu and two 2tb SSD's with the appropriate configuration.
I am a mac user and would like a windows computer for my upcoming observatory build.
Thanks all.
Vic
Well, if you are into using PixInsight, one thing to do is go to their benchmark page (https://pixinsight.com/benchmark/) and look up the performance you want. See clip here:
Click on the machine title and you can see more info at a high level of what the score was and the machine description:
Then click on the hyperlinked serial number and it will give you more details of the build:
The swap performance on that one is off the charts. I don't know how they achieved over 17GB/s swap performance, but that's a big reason why it scored so high. Something about the EPYCs, they seem to score really high on swap throughput (and I assume, in general, overall disk throughput.) The raw CPU performance matters, and having 192 threads is a big deal, but this system's I/O rates are so high that data transfer times there basically don't matter. Most of the highest scoring (well, lowest total time) benchmarks have high I/O throughput. More normal swap transfer rates are 3-6GB/s, with a pretty darn good "average" system scoring 8GB/s or so. It takes a lot of money to hit 7 seconds on the benchmark, and in all honesty, unless you are processing MASSIVE amounts of data, its utterly unnecessary.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Andrew Burwell:
Unless you’re ok doing preprocessing/calibration in Astro Pixel Processor which does use the GPU. Processing the same stack in Pix vs APP can go from 30 minutes to 6 minutes. It’s at least worth downloading the free trial so you can do your own benchmarks and compare on your current computer systems the difference in speed.
I would still do all my post processing in PixInsight. Seems like the writing is on the wall regarding adopting GPU for preprocessing.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Jon Rista:
The swap performance on that one is off the charts. I don't know how they achieved over 17GB/s swap performance, but that's a big reason why it scored so high. Something about the EPYCs, they seem to score really high on swap throughput (and I assume, in general, overall disk throughput.) The raw CPU performance matters, and having 192 threads is a big deal, but this system's I/O rates are so high that data transfer times there basically don't matter. Most of the highest scoring (well, lowest total time) benchmarks have high I/O throughput.
More normal swap transfer rates are 3-6GB/s, with a pretty darn good "average" system scoring 8GB/s or so. It takes a lot of money to hit 7 seconds on the benchmark, and in all honesty, unless you are processing MASSIVE amounts of data, its utterly unnecessary. I don't really know how cloud computing works so can't really say anything definitive and informed, but what is reported here by the user who reported it, they may not completely know what the swap disks really are. What I do see is the ratio between CPU time and Swap time for the one I posted above is similar to that I get with my computer. 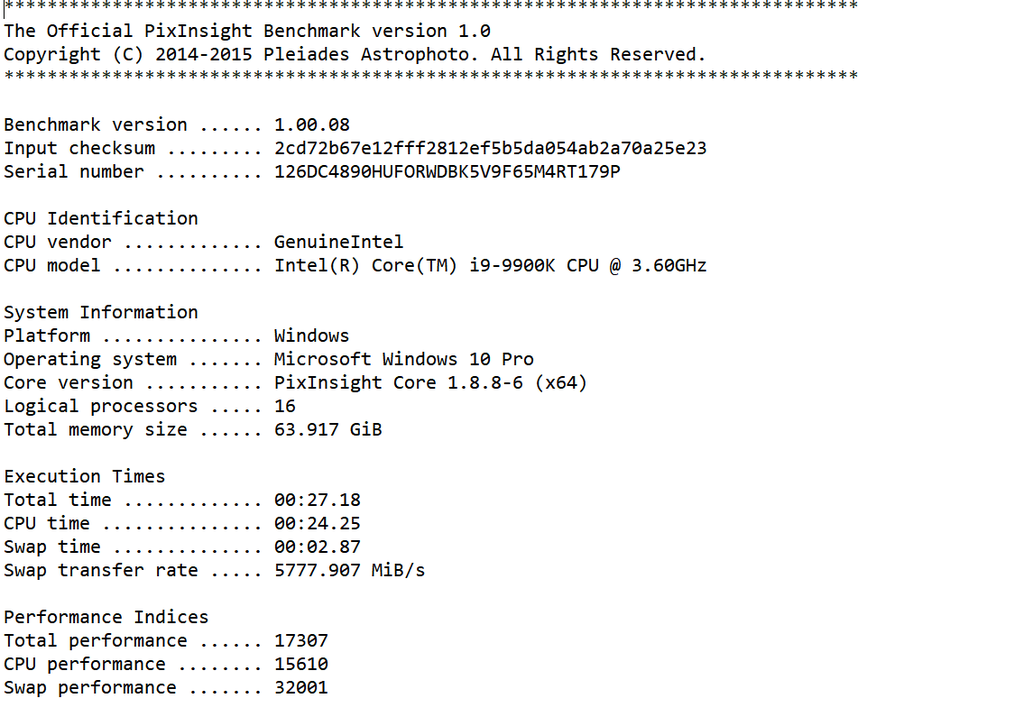 You pretty much nailed the swap performance for my system. And this seems to be consistent for those who have set up their swap disk folders well, per PI suggestions. I can't remember how it worked for me when I set up my swap folders on two RAM disks. I don't think it was that different, even though, on my computer, the access time and transfer rate to the RAM disks blew away even my NVMe drive. But the difference was between a fast blink and a blink in time... I may be wrong, but I think this ratio between CPU time and Swap time could be a good diagnostic for what one should target when they are playing with their Swap configuration. Clearly some who reported benchmarks should fix their swap configurations. I often think about when or if I should consider building a new computer for this processing stuff, now that I am getting on to 5 years post build. But I have to say that I cannot complain. Mine is no super computer, but with sufficient RAM, though just DDR4, 3200 and a PCIe 3.0 motherboard. And no where near the latest processor with the 9th gen i9 and 16 logical processors, its still reasonably competitive in its class. On the other hand, the good news for those building today is that any new stuff in the mid-range, should easily outperform my computer assuming they don't get saddled with a dog of a motherboard, or whatever. But everyone should be aware what that performance means in the real world, within the context of what software they are using. Paying $5-10x to get a time to completion that takes you from 20 seconds to 15 seconds does not seem to make much sense even if the computing community sees such gains as phenomenal!
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Alan Brunelle:
Jon Rista:
The swap performance on that one is off the charts. I don't know how they achieved over 17GB/s swap performance, but that's a big reason why it scored so high. Something about the EPYCs, they seem to score really high on swap throughput (and I assume, in general, overall disk throughput.) The raw CPU performance matters, and having 192 threads is a big deal, but this system's I/O rates are so high that data transfer times there basically don't matter. Most of the highest scoring (well, lowest total time) benchmarks have high I/O throughput.
More normal swap transfer rates are 3-6GB/s, with a pretty darn good "average" system scoring 8GB/s or so. It takes a lot of money to hit 7 seconds on the benchmark, and in all honesty, unless you are processing MASSIVE amounts of data, its utterly unnecessary.
I don't really know how cloud computing works so can't really say anything definitive and informed, but what is reported here by the user who reported it, they may not completely know what the swap disks really are. What I do see is the ratio between CPU time and Swap time for the one I posted above is similar to that I get with my computer.
You pretty much nailed the swap performance for my system. And this seems to be consistent for those who have set up their swap disk folders well, per PI suggestions. I can't remember how it worked for me when I set up my swap folders on two RAM disks. I don't think it was that different, even though, on my computer, the access time and transfer rate to the RAM disks blew away even my NVMe drive. But the difference was between a fast blink and a blink in time...
I may be wrong, but I think this ratio between CPU time and Swap time could be a good diagnostic for what one should target when they are playing with their Swap configuration. Clearly some who reported benchmarks should fix their swap configurations.
I often think about when or if I should consider building a new computer for this processing stuff, now that I am getting on to 5 years post build. But I have to say that I cannot complain. Mine is no super computer, but with sufficient RAM, though just DDR4, 3200 and a PCIe 3.0 motherboard. And no where near the latest processor with the 9th gen i9 and 16 logical processors, its still reasonably competitive in its class. On the other hand, the good news for those building today is that any new stuff in the mid-range, should easily outperform my computer assuming they don't get saddled with a dog of a motherboard, or whatever. But everyone should be aware what that performance means in the real world, within the context of what software they are using. Paying $5-10x to get a time to completion that takes you from 20 seconds to 15 seconds does not seem to make much sense even if the computing community sees such gains as phenomenal! It looks like that top-rated config uses UHP iSCSI disks for swap. I hadn't heard of that before, but apparently its some kind of networked storage that can be configured with multiple channels for rather insane performance. That may have something to do with it. Unless your RAM disks are vastly outperforming nVME drives, you are probably better off just sticking with nVME. Especially PCIe 5, if you have the opportunity, which last I checked, were outperforming RAM disks (which are emulated, hence the limits on performance.) IIRC ram disks were hitting ~7GB/s burst rates, while even a top rated PCIe 4 drive would hit nearly 8GB/s, and a PCIe 5 should hit 12.4GB/s. From what I read, the UHP iSCSI drives can be configured with multiple active channels, each of which can hit near 3GB/s per channel, and you can have a lot of channels. It seems like these UHP iSCSI drives have limited viability, they require special configuration with Linux, and I've had a hard time determining if its possible with windows (and if it is, its even more specialized configuration.) In your case, your swap performance is double your CPU performance, so I'd say you are probably thouroughly CPU bottlenecked right now. Note your times...it was just shy of 3 seconds spent on swap, and 24 seconds on CPU. So a CPU upgrade would be the most beneficial upgrade for you. That said...you are still under 30 seconds processing time. You would really have to weigh the value of an upgrade. At best, you might get down to about 15 seconds, which seems to be a rough limit for consumer grade equipment. Sub-10 seconds seems to be largely limited to EPYC systems (I honestly don't see the value in spending that kind of money on a rig just to shave a few seconds of compute time here or there during a manual processing session in PI...) To gai significantly on the cpu time front, I think it requires really scaling out the thread count (but if you do that, it could stress the I/O throughput more...you could hit swap a lot more frequently if you are doing your processing much faster). Those 96 core/192 thread EPYCs really push the envelope there, but boy are they costly ($5 grand or so just for the cpu).
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Tim, big fan here.
You’ve had all the big guns addressing your issue, but seems that not one took the time to look at the length of your subs.. 180secs. And your location, and lastly those shitty mounts 😊
Safely assuming that less subs will speed up your stacking time, why don’t you just double up or even 2.5 times your sub length. If I’m not mistaken, that will cut your stacking time in half and it will certainly not hurt your SNR.
I use 600, 900 secs and also drizzle with my twin TOAs unguided.
rafa
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Rafa:
Tim, big fan here.
You’ve had all the big guns addressing your issue, but seems that not one took the time to look at the length of your subs.. 180secs. And your location, and lastly those shitty mounts 😊
Safely assuming that less subs will speed up your stacking time, why don’t you just double up or even 2.5 times your sub length. If I’m not mistaken, that will cut your stacking time in half and it will certainly not hurt your SNR.
I use 600, 900 secs and also drizzle with my twin TOAs unguided.
rafa Great observations and questions, Rafa! I've been talking with Mark Hanson, and sub length is definitely on the table. He does pretty much all 900s subs. My concerns there are wind gusts in the New Mexico desert and low 737 flyovers to and from the Albuquerque airport. But I think I may start going to 300-600 instead of 180-300 and see what happens. That would help with the stacking issue. But I would still like to really improve interactive response time during post.
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.
Timothy Martin:
Rafa:
Tim, big fan here.
You’ve had all the big guns addressing your issue, but seems that not one took the time to look at the length of your subs.. 180secs. And your location, and lastly those shitty mounts 😊
Safely assuming that less subs will speed up your stacking time, why don’t you just double up or even 2.5 times your sub length. If I’m not mistaken, that will cut your stacking time in half and it will certainly not hurt your SNR.
I use 600, 900 secs and also drizzle with my twin TOAs unguided.
rafa
Great observations and questions, Rafa! I've been talking with Mark Hanson, and sub length is definitely on the table. He does pretty much all 900s subs. My concerns there are wind gusts in the New Mexico desert and low 737 flyovers to and from the Albuquerque airport. But I think I may start going to 300-600 instead of 180-300 and see what happens. That would help with the stacking issue. But I would still like to really improve interactive response time during post. Find the optimal balance point for your system. Not every system is the same, and 900s is pretty long for modern systems and cameras. There are benefits to longer subs, there are benefits to shorter subs, somewhere in the middle is usually the optimum. There are certainly some key detractors to very long subs like 900s or longer, as losing just one of those can mean a non-trivial amount of your total integration. If you really want longer subs, though, you can always use a lower gain on a modern CMOS camera. There is usually a gain mode and gain setting where read noise is reasonable and dynamic range is extremely high, ands you can get very good quality subs with long to very long exposures, if that is something you need. But, you will want to make sure you can handle it, and that your tracking is consistently good enough to avoid sub loss (you mentioned wind gusts...) If you are at 180 seconds right now, moving up to 300 seconds or even 360 seconds could halve your sub count. You may not need to move to a very low gain either. Something else to consider...even if you have some slightly clipped stars at 180 seconds, doubling your exposure does not necessarily mean that clipped stars change much, or that you even get that many more clipped stars. The nature of stellar signal profiles is that the central pixels are often 1.5-3x brighter than the next brightest pixels of the star, so you can often increase exposure by quite a lot, without really affecting stellar clipping much. So you may have plenty of room to experiment even at your current gain (which would have the benefit of not requiring additional calibration frames to be taken.)
|
You cannot like this item. Reason: "ANONYMOUS".
You cannot remove your like from this item.
Editing a post is only allowed within 24 hours after creating it.
You cannot Like this post because the topic is closed.
Copy the URL below to share a direct link to this post.
This post cannot be edited using the classic forums editor.
To edit this post, please enable the "New forums experience" in your settings.